

为什么更智能的AI缓存有时会导致一切变得更慢
The New Stack
·



比较最佳开源向量数据库
Redis Blog
·


站点升级手记 05:性能优化,从缓存、CDN 到响应耗时监控
mongona news
·
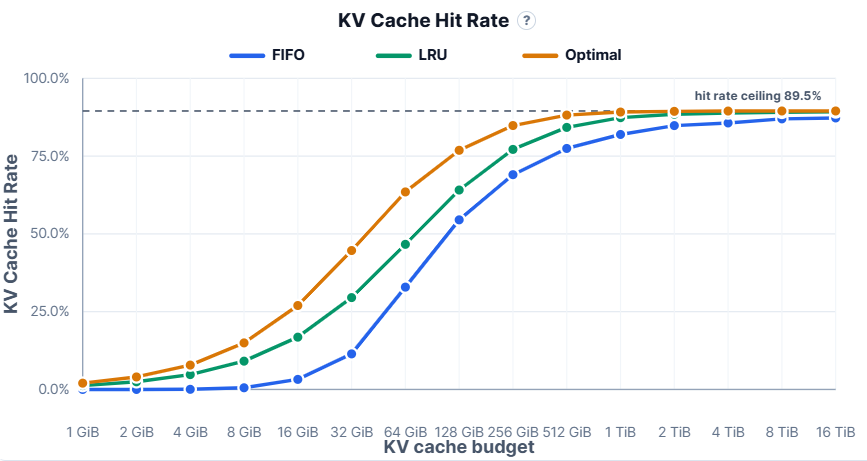
我们需要多少KV缓存预算来支持LLM服务?
Home | KVCache.ai
·

Web缓存欺骗进阶(二)|特殊分隔符解析差异漏洞深度总结
FreeBuf网络安全行业门户
·


Redis与Memorystore:2026年的关键差异
Redis Blog
·
