
Uber如何通过集成缓存每秒处理超过1.5亿次读取
内容提要
Uber的CacheFront系统通过缓存技术提高数据读取效率,解决数据一致性问题,实现99.9%的缓存命中率,工程团队因此减少了70%以上的事件处理和调试时间。
关键要点
-
Uber的CacheFront系统通过缓存技术提高数据读取效率,解决数据一致性问题。
-
CacheFront实现了99.9%的缓存命中率,显著减少了事件处理和调试时间。
-
Uber的存储系统Docstore由查询引擎、存储引擎和缓存逻辑组成。
-
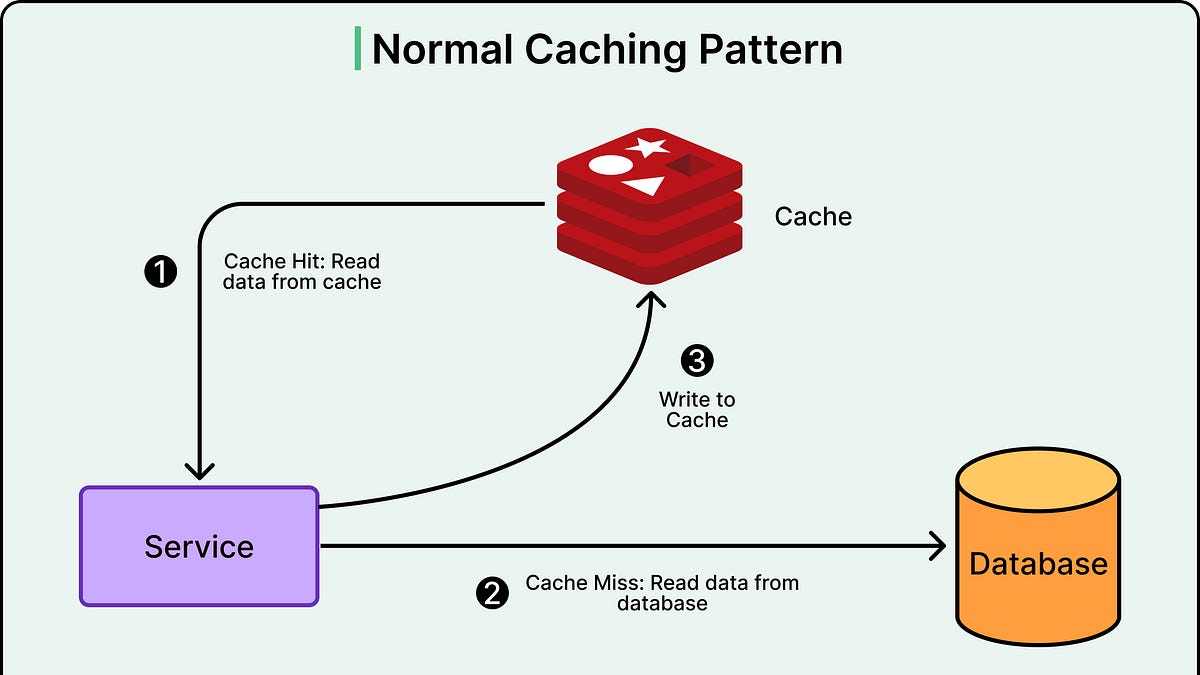
缓存技术通过存储频繁访问的数据来减少数据库负载和延迟。
-
写操作引入了复杂性,尤其是条件更新时,缓存失效的管理变得困难。
-
Uber最初使用Flux系统进行异步缓存失效管理,但存在一致性问题。
-
通过将删除操作转换为软删除和使用单调时间戳,Uber实现了同步缓存失效。
-
CacheFront现在运行三种机制来保持缓存一致性:TTL过期、Flux异步失效和新的写路径失效。
-
Cache Inspector工具用于验证缓存一致性,结果显示几乎没有过期值。
-
CacheFront系统在高峰时段每秒处理超过1.5亿次请求,且一致性保证得到了提升。
延伸解读
缓存技术的重要性
Uber的CacheFront系统通过缓存技术显著提高了数据读取效率,减少了数据库的负载和延迟。对于拥有数百万用户的应用来说,直接从数据库读取数据会导致延迟,影响用户体验。缓存技术通过存储频繁访问的数据,确保用户请求能够快速响应,提升了整体服务质量。
一致性挑战与解决方案
在缓存系统中,一致性问题是一个关键挑战。Uber通过将删除操作转为软删除和使用单调时间戳,成功实现了同步缓存失效。这种方法不仅提高了数据一致性,还确保了在高并发情况下,用户能够读取到最新的数据,避免了因缓存失效导致的用户体验下降。
Cache Inspector的作用
Uber开发的Cache Inspector工具用于验证缓存的一致性,能够有效监测缓存中的过期值。通过与MySQL的binlog事件进行对比,Cache Inspector确保了在长达一周的时间内,几乎没有过期值。这一工具的使用使得Uber能够自信地提高TTL值,从而在不牺牲一致性的情况下,提升系统性能。
延伸问答
Uber的CacheFront系统如何提高数据读取效率?
CacheFront通过缓存技术存储频繁访问的数据,减少数据库负载和延迟,从而提高数据读取效率。
CacheFront系统的缓存命中率是多少?
CacheFront实现了超过99.9%的缓存命中率。
Uber是如何解决缓存一致性问题的?
Uber通过将删除操作转换为软删除和使用单调时间戳,实现了同步缓存失效,从而解决了缓存一致性问题。
CacheFront在高峰时段每秒处理多少请求?
CacheFront在高峰时段每秒处理超过1.5亿次请求。
写操作对缓存系统带来了哪些挑战?
写操作引入了复杂性,尤其是条件更新时,缓存失效的管理变得困难,可能导致用户读取到过时的数据。
Cache Inspector工具的作用是什么?
Cache Inspector用于验证缓存一致性,比较数据库变更与Redis中的数据,跟踪过期值和过期持续时间。
