
推理速度提升3倍,多伦多大学等提出dnaHNet,基因组学习计算成本降低近4倍
内容提要
dnaHNet模型是一种新型基因组学习模型,通过动态分块机制自我学习序列结构,显著提升了计算效率和表达能力。在变异效应预测和基因必需性分类等任务中表现优异,计算成本降低3.89倍,为基因组解析提供了新思路。
关键要点
-
dnaHNet模型是一种新型基因组学习模型,通过动态分块机制自我学习序列结构。
-
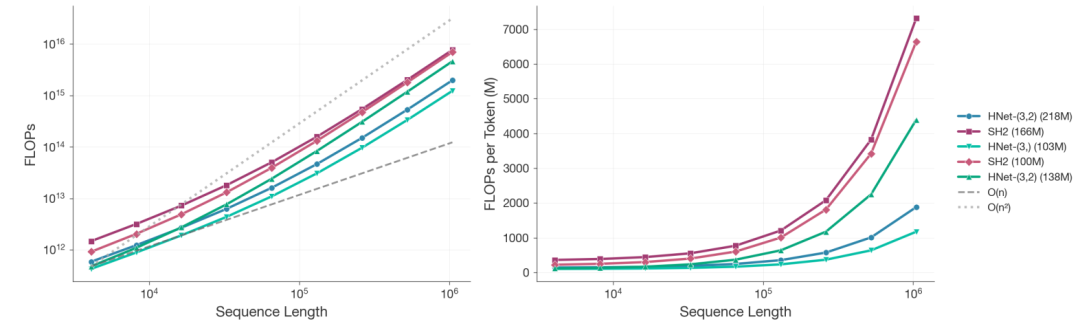
dnaHNet在计算效率上超越了StripedHyena2,推理速度较Transformer提升3倍以上。
-
该模型在变异效应预测和基因必需性分类等任务中表现优异,计算成本降低3.89倍。
-
dnaHNet能够学习上下文相关的生物学分词,适配不同功能区域。
-
研究构建了覆盖85,205种原核生物的多层次基因组数据集,包含约1,440亿个核苷酸。
-
模型通过动态决定分块方式,使建模粒度能够随上下文自适应变化,提升了对生物功能的刻画能力。
-
dnaHNet在无监督条件下重建基因组的功能组织结构,为DNA语法的解析提供了可解释的计算路径。
延伸解读
dnaHNet的创新机制
dnaHNet模型通过动态分块机制自我学习序列结构,避免了传统固定分词对生物学功能单元的割裂。这种创新设计不仅提升了表达能力,还降低了计算成本,为基因组学习提供了新的思路。
计算效率的显著提升
与现有模型相比,dnaHNet在推理速度上提升了3倍以上,计算成本降低近4倍。这一进展使得在大规模基因组数据分析中,研究人员能够更高效地进行变异效应预测和基因必需性分类等任务。
多层次数据集的构建
研究团队构建了覆盖85,205种原核生物的多层次基因组数据集,包含约1,440亿个核苷酸。这一数据集为dnaHNet的训练和评估提供了坚实基础,确保了模型在不同生物学任务中的适用性和准确性。
延伸问答
dnaHNet模型的主要创新点是什么?
dnaHNet模型通过动态分块机制自我学习序列结构,显著提升了计算效率和表达能力。
dnaHNet在计算效率上与其他模型相比如何?
dnaHNet的推理速度较Transformer提升超过3倍,计算成本降低约3.89倍。
dnaHNet模型在基因组学习中有哪些应用?
该模型在变异效应预测和基因必需性分类等任务中表现优异。
dnaHNet如何处理基因组数据的建模?
dnaHNet将基因组学习统一为自回归序列预测任务,通过动态决定分块方式适应上下文。
研究中使用的数据集包含哪些内容?
数据集覆盖85,205种原核生物,包含约1,440亿个核苷酸,经过严格的质控和去冗余处理。
dnaHNet模型的结构设计有什么特点?
dnaHNet采用分层架构,结合编码器、主干网络和解码器,增强对局部结构的刻画能力。
