

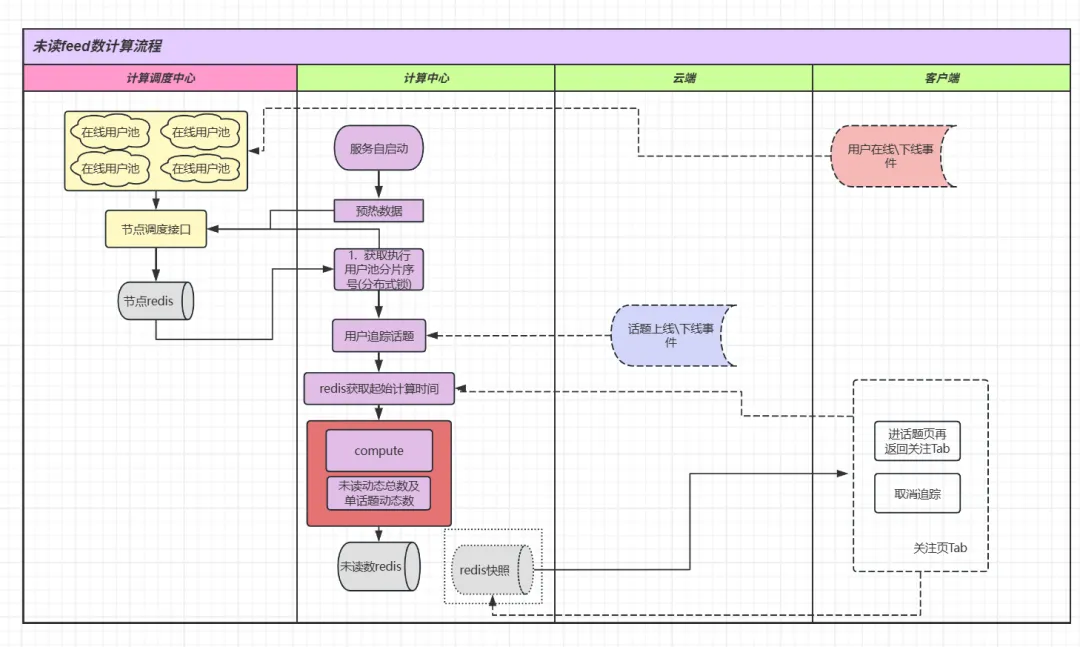
搜狐技术:未读消息数系统设计
实时互动网
·

注意力机制之后是什么?这家初创公司表示它已经知道了。
The New Stack
·

Modular:零日:MiniMax M3在Modular云上的开放权重
Modular Blog
·

为长时间运行的代理构建上下文修剪管道
MachineLearningMastery.com
·

SilverTorch:索引即模型——推荐系统的新检索范式
Engineering at Meta
·

Google Axion实例现已在Elastic Cloud托管上可用
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
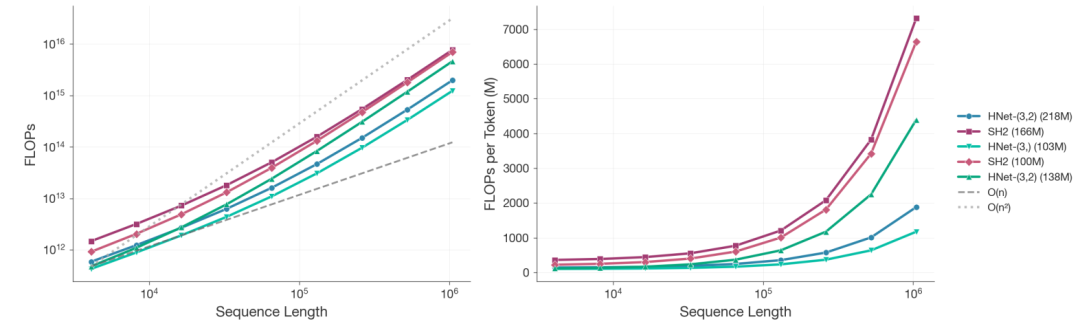
推理速度提升3倍,多伦多大学等提出dnaHNet,基因组学习计算成本降低近4倍
HyperAI超神经
·
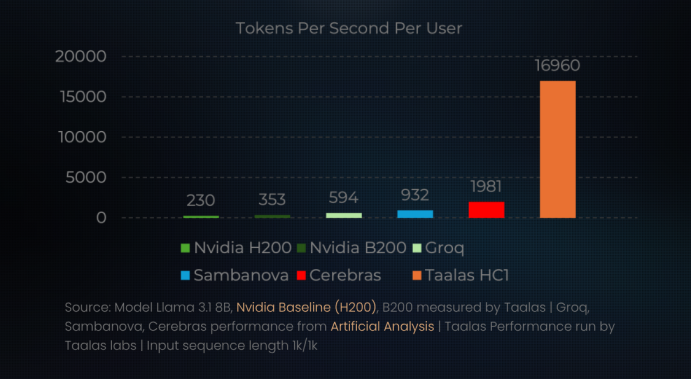
复盘AI芯片技术路线 专用芯片复刻矿机历程
dotNET跨平台
·
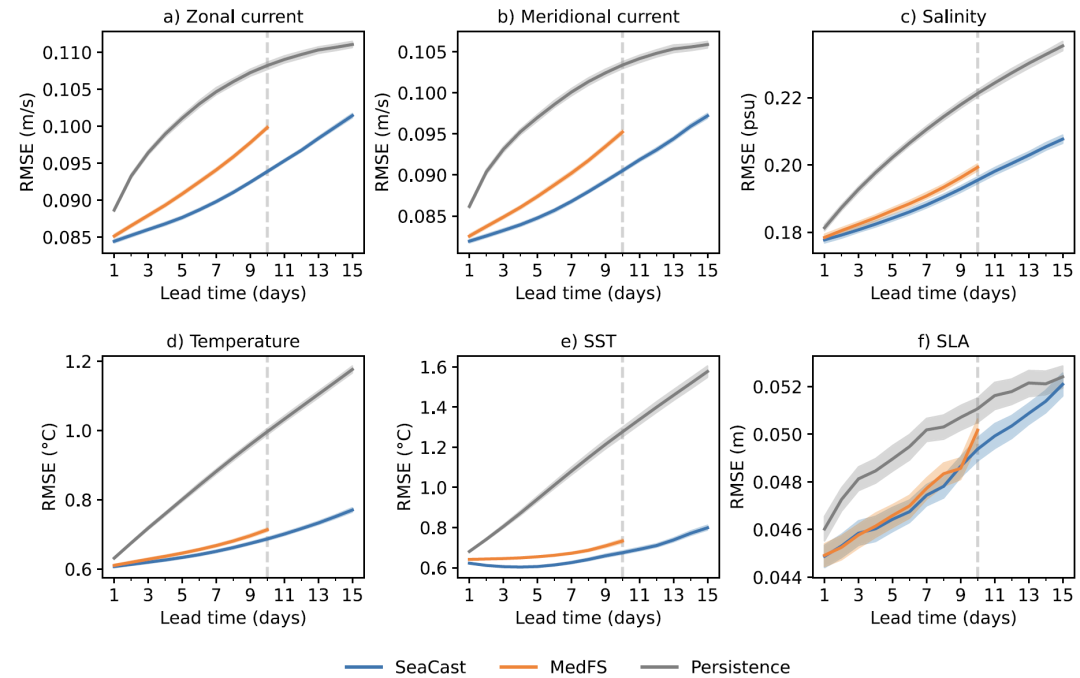
20秒完成15天预报,欧洲科研团队提出高分辨率区域海洋预报模型SeaCast
HyperAI超神经
·
推动vLLM WideEP和大规模服务在Blackwell平台上的成熟(第一部分)
vLLM Blog
·

MoE比你想象的更强大:基于RoE的超并行推理扩展
Apple Machine Learning Research
·
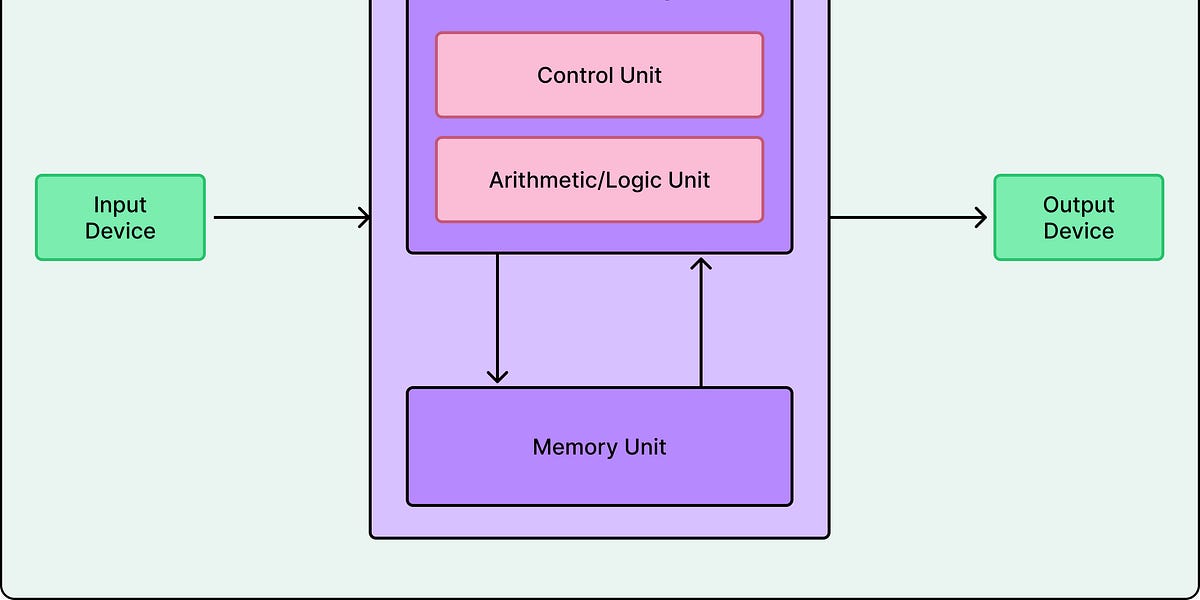
谷歌的张量处理单元(TPU)是如何工作的?
ByteByteGo Newsletter
·
