
Triton Flash Attention 内核详解:前向传播
内容提要
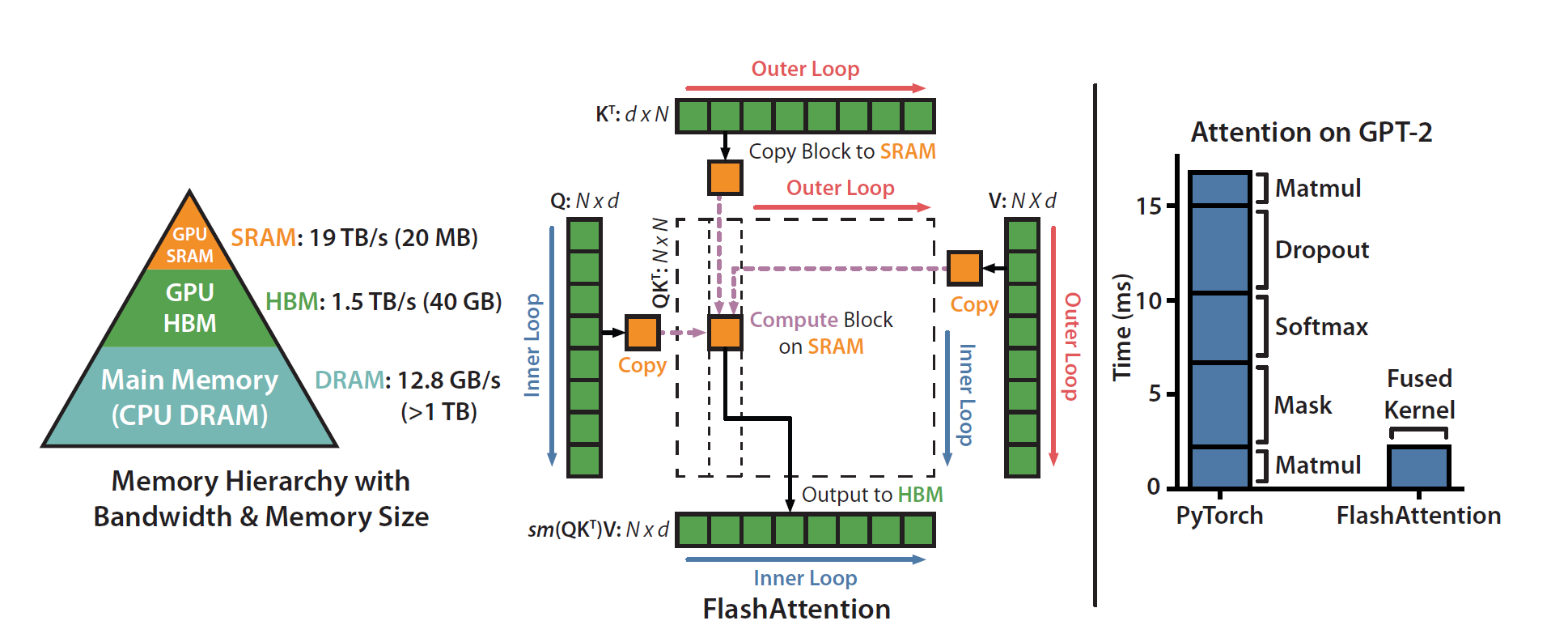
本文探讨了Triton实现的FlashAttention机制,强调其在GPU内存管理上的创新。FlashAttention通过分块处理输入,减少内存I/O瓶颈,提升计算效率。文章介绍了核心设计,包括在线softmax方法和相对位置偏差的引入,展示了在高性能GPU内核中实现高效注意力机制的方式。
关键要点
-
FlashAttention机制通过分块处理输入,解决了标准注意力计算中的内存瓶颈问题。
-
该机制采用在线softmax方法,能够在不需要完整得分矩阵的情况下进行快速计算。
-
FlashAttention通过在GPU的快速SRAM中进行计算,显著减少了内存I/O的需求。
-
引入相对位置偏差的机制,使得模型能够在注意力得分中考虑相对位置。
-
Triton实现的FlashAttention通过优化内存管理和计算效率,提升了高性能GPU内核的表现。
延伸解读
FlashAttention的内存管理优势
FlashAttention通过分块处理输入数据,显著减少了GPU内存I/O瓶颈。这种方法不仅提高了计算效率,还使得在处理长序列时,GPU能够更有效地利用其快速的SRAM,从而提升整体性能。对于需要处理大规模数据的应用,FlashAttention的内存管理策略尤为重要。
在线Softmax的创新
FlashAttention引入的在线softmax方法,允许在不需要完整得分矩阵的情况下进行快速计算。这一创新不仅提高了计算速度,还保持了结果的准确性。对于需要实时处理的任务,如自然语言处理和图像识别,这种方法能够显著提升响应速度和效率。
相对位置偏差的引入
FlashAttention中引入的相对位置偏差机制,使得模型在计算注意力得分时能够考虑输入序列中元素的相对位置。这一特性对于处理具有顺序关系的数据(如文本和时间序列)非常关键,能够帮助模型更好地理解上下文信息,从而提升预测的准确性。
延伸问答
FlashAttention机制是如何解决内存瓶颈问题的?
FlashAttention通过分块处理输入,将Q、K和V分成小块,使其能够适应GPU的快速SRAM,从而减少内存I/O瓶颈。
在线softmax方法在FlashAttention中有什么作用?
在线softmax方法允许FlashAttention在不需要完整得分矩阵的情况下,逐块计算softmax归一化因子,从而提高计算速度。
相对位置偏差是如何在FlashAttention中实现的?
FlashAttention通过引入一个可选的log-decay机制,利用预计算的累积和g_cumsum,将相对位置偏差融入注意力得分的计算中。
FlashAttention如何提高GPU内核的计算效率?
FlashAttention通过优化内存管理和采用高效的分块计算方法,显著减少了内存I/O需求,从而提升了GPU内核的计算效率。
Triton在FlashAttention中的作用是什么?
Triton用于实现FlashAttention的高性能GPU内核,通过其特定的编程模型优化内存使用和计算过程。
FlashAttention的核心设计理念是什么?
FlashAttention的核心设计理念是I/O感知,通过分块处理和在线softmax方法,优化注意力计算以适应GPU的内存架构。
