机器之心数据服务现已上线,提供高效稳定的数据获取服务,帮助用户轻松获取所需数据。
本研究提出了FLASH-D,一种改进的变换器注意力机制,通过将Softmax计算与矩阵运算结合,显著提高了计算效率,降低了硬件面积和功耗,具有实际应用潜力。
FlashAttention通过优化注意力算法的内存使用,提升了性能。其核心在于分块处理K、V矩阵,并利用在线softmax技术减少内存读写,从而实现高效的注意力计算。
本文总结了研究论文《视觉指南揭示FlashAttention如何提高AI内存管理效率》。FlashAttention算法通过可视化优化内存管理,减少数据在快慢内存间的移动,从而提升深度学习的IO效率和内存层次结构。
本文介绍了FlashAttention,一种高效的注意力算法,显著提升了Transformer模型的速度和性能。通过优化内存使用和引入新技术,FlashAttention在大型语言模型中实现了更高效的推理,减少了内存需求并提高了计算速度。研究还探讨了量化技术和新型推理框架,推动了大型语言模型在内存有限设备上的应用。
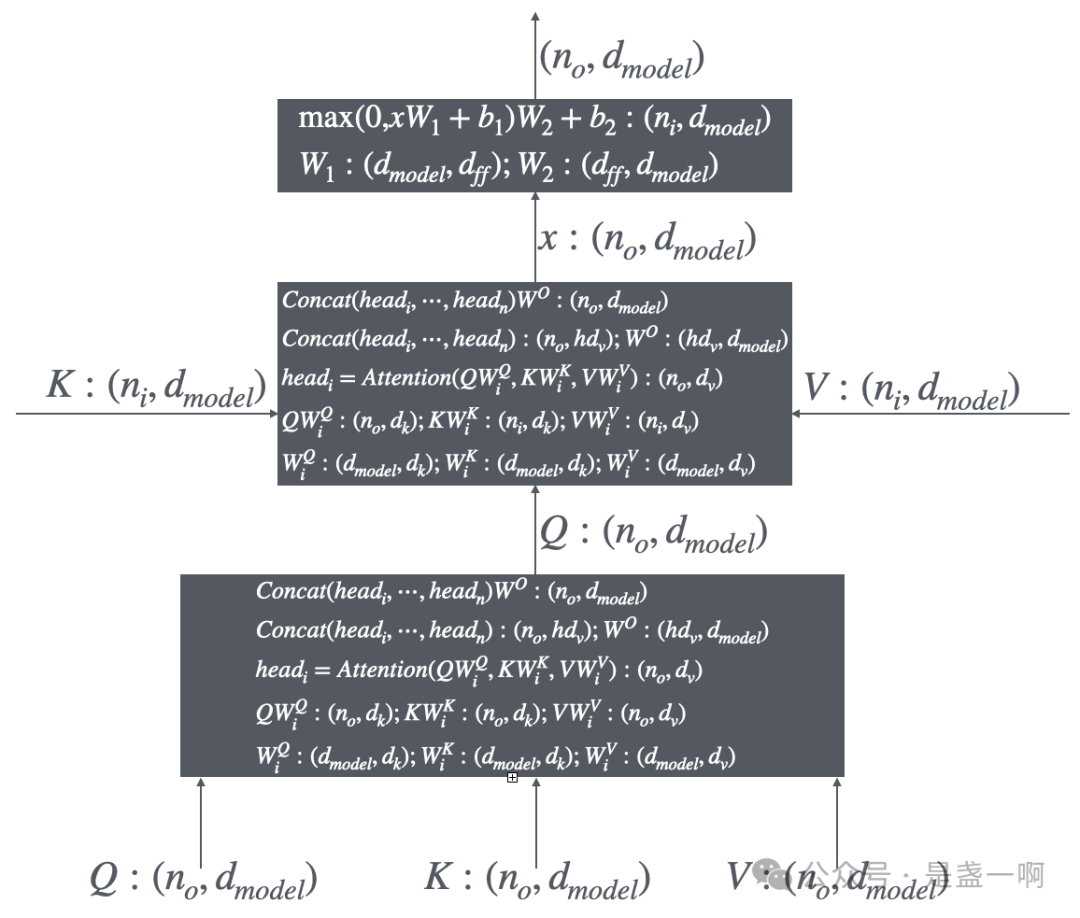
本文总结了Transformer模型的结构,重点介绍了编码器和解码器的输入输出关系。编码器处理用户输入的token并生成中间层输出;解码器根据编码器的输出逐步生成新的token。讨论了Masked Multi-Head Attention的作用,强调其对解码过程中因果性的影响,并指出GPT与Transformer的区别,GPT仅包含解码器并应用masked机制。
PyTorch团队引入了FlexAttention,一个灵活的API,允许用户使用几行PyTorch代码实现多个注意力变体。通过torch.compile将其降低到一个融合的FlashAttention内核中,生成了一个不会占用额外内存且性能可与手写内核相媲美的FlashAttention内核。FlexAttention具有令人惊讶的表达能力,可以满足大多数用户对注意力变体的需求。
英伟达与FlashAttention-3合作,优化H100芯片,提升训练速度和计算吞吐量。FlashAttention-3通过IO感知优化和分块处理,充分利用Hopper架构特点。引入异步方式、乒乓调度和两阶段GEMM-softmax流水线方案等技术,提高GPU利用率。采用FP8精度、分块量化和非相干处理技术,提高计算精度。在测试中,FlashAttention-3在注意力基准测试和消融实验中表现出色,速度快3-16倍。
本文介绍了优化的注意力机制,如FlashAttention和FlashAttention-2,旨在提升Transformer模型的效率和性能。通过减少内存读取次数和引入新算法,训练速度显著提高,尤其在长序列上表现优异。此外,提出的可分解关注机制将计算复杂度降低至O(N),并保持注意力矩阵的完整性,展现出在多种应用中的潜力。
本文介绍了华为云Ascend C的FlashAttention算子性能优化实践,通过计算等价和切分有效降低HBM数据访问量,提升Attention处理性能。优化手段包括tiling基本块大小调整、核间负载均衡、CV流水并行、MTE2流水优化以及FixPipe流水优化等。实测在典型场景中性能提升4倍左右。开发者可参考此案例进行融合算子的性能优化。
本文介绍了FlashAttention-2前向传递的优化实现,使用了自定义融合的CUDA内核,适应NVIDIA Hopper架构,并使用开源的CUTLASS库编写。通过解释在线softmax和连续的GEMM内核融合的挑战和技术,利用Hopper特定的Tensor Memory Accelerator(TMA)和Warpgroup Matrix-Multiply-Accumulate(WGMMA)指令,定义和转换CUTLASS布局和张量,重叠复制和GEMM操作,并选择最优瓦片大小,平衡寄存器压力和共享内存利用率。在单个H100 PCIe GPU上的对比性测试中,与针对上一代NVIDIA Ampere架构进行优化的FlashAttention-2版本相比,FLOPs/s高出20-50%。
本文介绍了Multi-Query Attention技术,可共享Key和Value矩阵,提高推理速度和降低显存占用。MQA和MHA在代码实现上有差异,本地加载ChatGLM2-6B模型。基于P-Tuning v2的微调方法可将参数量减少到原来的0.1%,微调后的模型效果更好。
完成下面两步后,将自动完成登录并继续当前操作。