
从 transformer 到 FlashAttention 再到 PagedAttention(1)
内容提要
本文总结了Transformer模型的结构,重点介绍了编码器和解码器的输入输出关系。编码器处理用户输入的token并生成中间层输出;解码器根据编码器的输出逐步生成新的token。讨论了Masked Multi-Head Attention的作用,强调其对解码过程中因果性的影响,并指出GPT与Transformer的区别,GPT仅包含解码器并应用masked机制。
关键要点
-
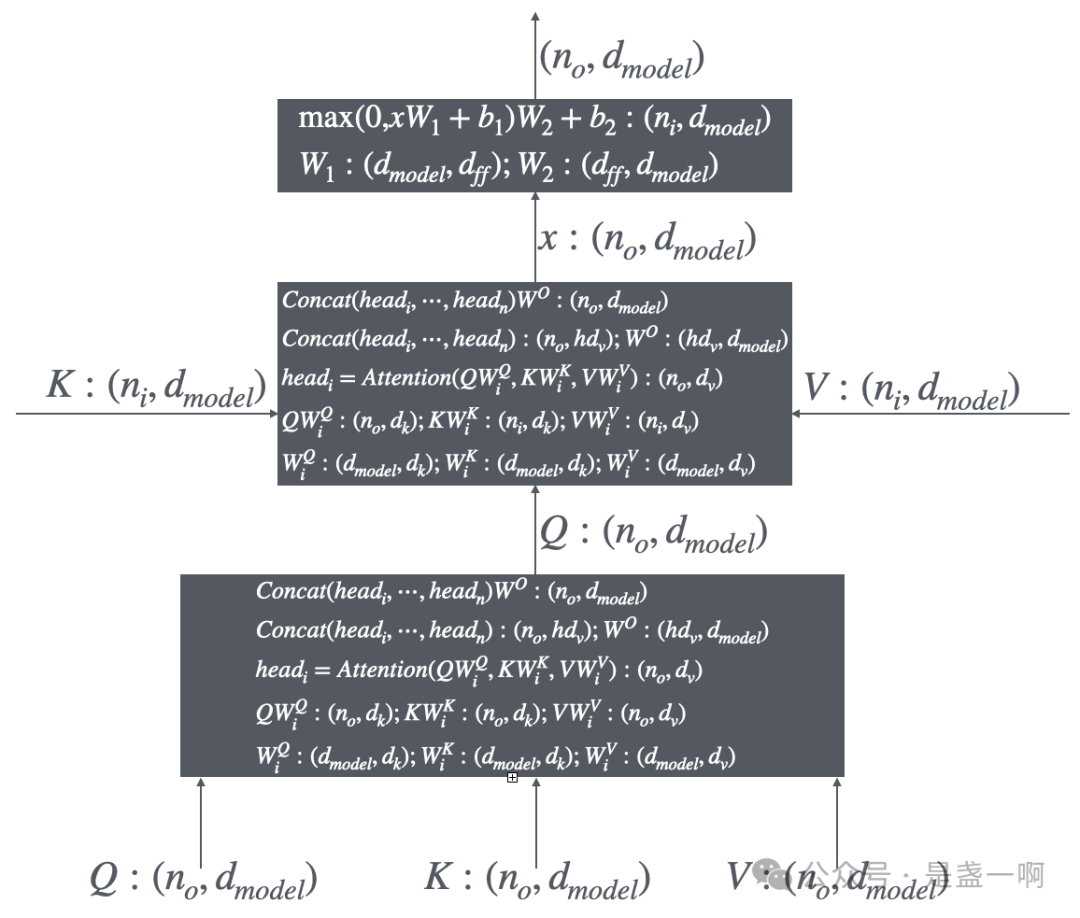
Transformer模型由编码器和解码器组成,编码器处理用户输入的token并生成中间层输出。
-
编码器的输入是用户输入的token,输出作为解码器的输入。
-
解码器逐步生成新的token,输入包括之前生成的token和特殊标记<SOS>。
-
Masked Multi-Head Attention在解码过程中起到关键作用,确保因果性,防止未来信息泄露。
-
GPT模型仅包含解码器,使用masked机制,用户输入的token仅考虑其之前的token。
延伸解读
Transformer模型的结构与功能
Transformer模型由编码器和解码器组成,编码器负责处理用户输入的token并生成中间层输出,而解码器则根据这些输出逐步生成新的token。理解这两者的输入输出关系,有助于深入掌握模型的工作原理,特别是在自然语言处理任务中的应用。
Masked Multi-Head Attention的重要性
Masked Multi-Head Attention在解码过程中至关重要,它确保了因果性,防止未来信息泄露。如果没有mask机制,解码器可能会混淆当前token与未来token的关系,从而影响生成结果的准确性。因此,理解mask的作用对于优化模型性能至关重要。
GPT与Transformer的区别
虽然GPT与Transformer有相似之处,但它们的结构和功能存在显著差异。GPT仅包含解码器,并且在处理用户输入时应用masked机制,这意味着它只考虑之前的token。这种设计使得GPT在处理某些句子结构时可能不够灵活,尤其是倒装句。
延伸问答
Transformer模型的基本结构是什么?
Transformer模型由编码器和解码器组成,编码器处理用户输入的token并生成中间层输出,解码器根据编码器的输出逐步生成新的token。
编码器和解码器之间的输入输出关系是怎样的?
编码器的输入是用户输入的token,输出作为解码器的输入,解码器逐步生成新的token,输入包括之前生成的token和特殊标记<SOS>。
Masked Multi-Head Attention在解码过程中有什么作用?
Masked Multi-Head Attention确保因果性,防止未来信息泄露,从而保证解码过程的正确性。
GPT与Transformer有什么区别?
GPT仅包含解码器,并应用masked机制,用户输入的token仅考虑其之前的token,而Transformer的编码器没有masked机制。
解码器的输入是如何生成的?
解码器的输入包括最低层的<SOS>标记和之前生成的token,逐步生成新的token。
为什么在解码过程中需要使用masked机制?
使用masked机制是为了确保解码过程中的因果性,避免模型在生成token时泄露未来的信息。
