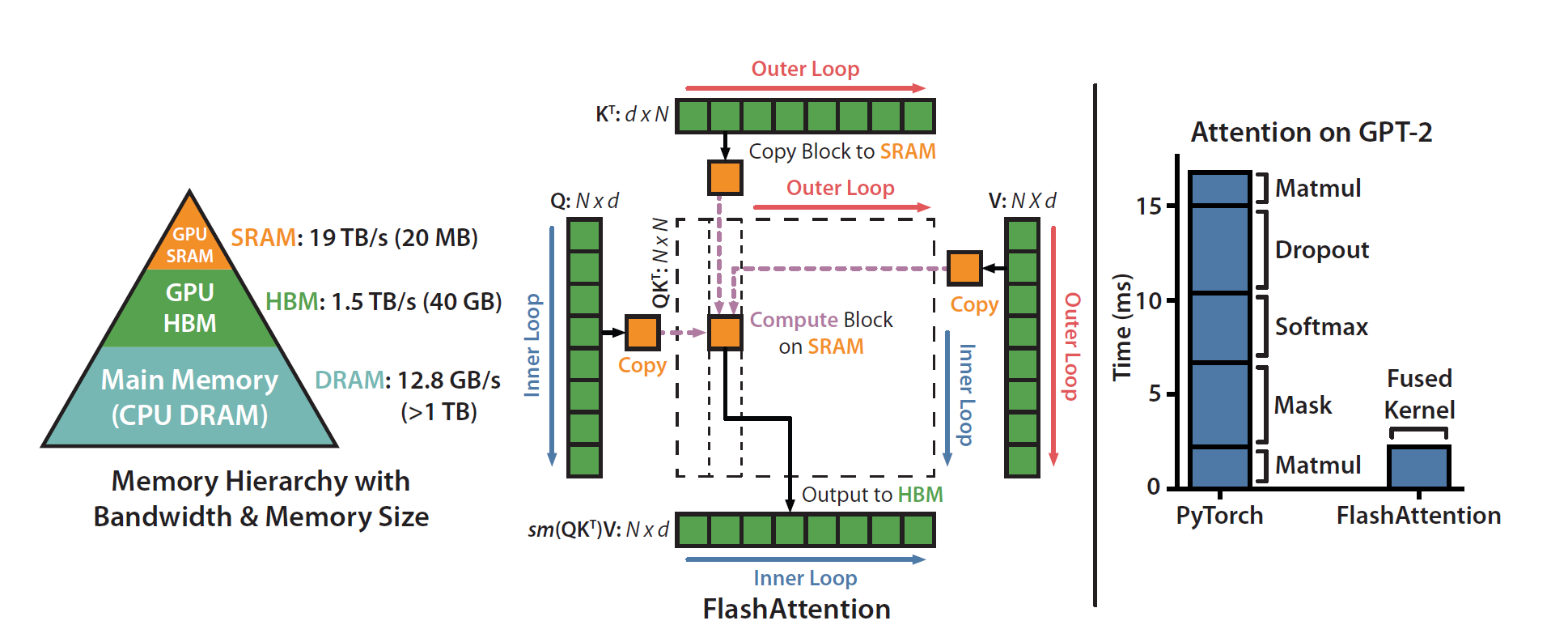
本文探讨了Triton实现的FlashAttention机制,强调其在GPU内存管理上的创新。FlashAttention通过分块处理输入,减少内存I/O瓶颈,提升计算效率。文章介绍了核心设计,包括在线softmax方法和相对位置偏差的引入,展示了在高性能GPU内核中实现高效注意力机制的方式。
完成下面两步后,将自动完成登录并继续当前操作。