
复盘AI芯片技术路线 专用芯片复刻矿机历程
内容提要
Taalas公司推出了一种新型AI硬件,将Llama 3.1模型直接固化在芯片中,显著降低输出延迟并提升计算效率。这种“模型即硬件”的设计克服了传统GPU的内存瓶颈,适用于复杂决策和实时推理,展现出优越的能效和成本优势。
关键要点
-
Taalas公司推出新型AI硬件,将Llama 3.1模型固化在芯片中,降低输出延迟,提升计算效率。
-
这种“模型即硬件”的设计克服了传统GPU的内存瓶颈,适用于复杂决策和实时推理。
-
当前AI算力的核心限制是内存墙,导致数据传输消耗大量时间与能耗。
-
Taalas的方案通过硬件定制,省去参数调取环节,提升了计算效率。
-
主流AI芯片架构分为三种:英伟达GPU、传统NPU/AI加速器和Taalas的ASIC。
-
Taalas的ASIC方案通过金属布线固化模型权重,移除数据搬运逻辑,提升能效与成本控制。
-
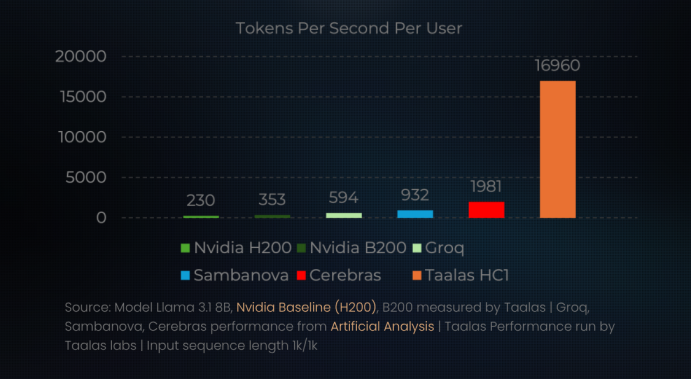
Taalas HC1芯片在推理速度和能效比上超越传统GPU,生产成本降低约20倍。
-
该方案在复杂决策、具身智能和本地化计算等场景中展现出优势。
-
Taalas的极短工程流片周期使得芯片更新与模型迭代同步,降低了沉没成本风险。
-
AI芯片的发展趋势是向极致专用性能倾斜,专用芯片在推理端的优势逐步显现。
-
不同架构的AI芯片在生态中并非零和博弈,而是互补关系,关键在于挖掘比较优势。
延伸解读
内存墙的挑战与解决方案
当前AI算力的核心限制是内存墙,导致数据传输消耗大量时间与能耗。Taalas通过将模型参数固化在芯片中,直接消除了数据搬运的环节,从而显著提升了计算效率。这一创新不仅解决了内存瓶颈问题,还为实时推理和复杂决策提供了更强的支持。
专用芯片的市场前景
Taalas的ASIC方案展现出在特定应用场景中的优势,尤其是在复杂决策和实时推理方面。随着AI技术的不断发展,专用芯片的需求将逐渐增加,可能会重塑现有的AI算力市场格局。未来,专用芯片在推理端的能效比和性价比优势将愈加明显。
灵活性与专用化的权衡
尽管Taalas的方案在性能上具有显著优势,但其固化设计也带来了灵活性不足的问题。当底层模型更新时,已流片的芯片可能面临沉没成本的风险。因此,如何在专用化与灵活性之间找到平衡,将是未来AI芯片发展的重要课题。
延伸问答
Taalas的新型AI硬件有什么特点?
Taalas的新型AI硬件将Llama 3.1模型固化在芯片中,显著降低输出延迟并提升计算效率,采用“模型即硬件”的设计。
Taalas的ASIC方案如何克服内存瓶颈?
Taalas的ASIC方案通过金属布线固化模型权重,移除数据搬运逻辑,从而提升能效与成本控制,避免了内存带宽的限制。
Taalas HC1芯片的性能如何?
Taalas HC1芯片在推理速度上可达16,000至17,000 Tokens/秒,系统延迟控制在1毫秒以内,能效比提升约10倍,生产成本降低约20倍。
Taalas的技术路线与传统GPU有何不同?
Taalas的技术路线通过硬件定制直接固化模型,避免了传统GPU在数据搬运上的效率损耗,专注于特定模型的优化。
Taalas的方案在实际应用中有哪些优势?
Taalas的方案在复杂决策、具身智能和本地化计算等场景中展现出优势,能够提供低延迟和高效能的计算支持。
Taalas的ASIC方案面临哪些挑战?
Taalas的ASIC方案面临的挑战包括灵活性问题,特别是在底层模型更新时,已流片的芯片可能成为沉没成本。
