
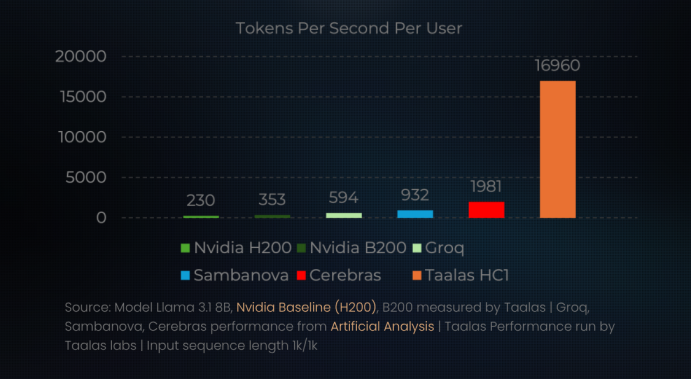
复盘AI芯片技术路线 专用芯片复刻矿机历程
dotNET跨平台
·

NVIDIA在MLPerf Training v5.1基准测试中获胜
NVIDIA Blog
·

教程:使用谷歌云Cloud Run进行GPU加速的无服务器推理
The New Stack
·

模块化:MAX 24.5 - Llama 3.1 的顶级 CPU 性能
Modular Blog
·

将 Llama 3 付诸实践
Engineering at Meta
·


AI顶会KDD’25今日截稿!Llama 3.1中文微调数据集已上线,超大模型一键部署
HyperAI超神经
·

最可能做出 AI 超级应用的,不是 OpenAI
爱范儿
·



