
读完 DeepSeek-V4 技术报告:这次最值得看的,不是“更大”,而是“更省”
内容提要
DeepSeek-V4技术报告强调通过改进注意力机制和优化器,提高超长上下文处理效率,能够高效处理1M上下文,降低计算和缓存成本。模型在中文写作和白领任务中表现良好,但在复杂任务上仍需提升。整体目标是解决长上下文的成本问题,提供完整的技术方案。
关键要点
-
DeepSeek-V4技术的核心问题是如何高效处理超长上下文,尤其是1M tokens的上下文,降低计算和缓存成本。
-
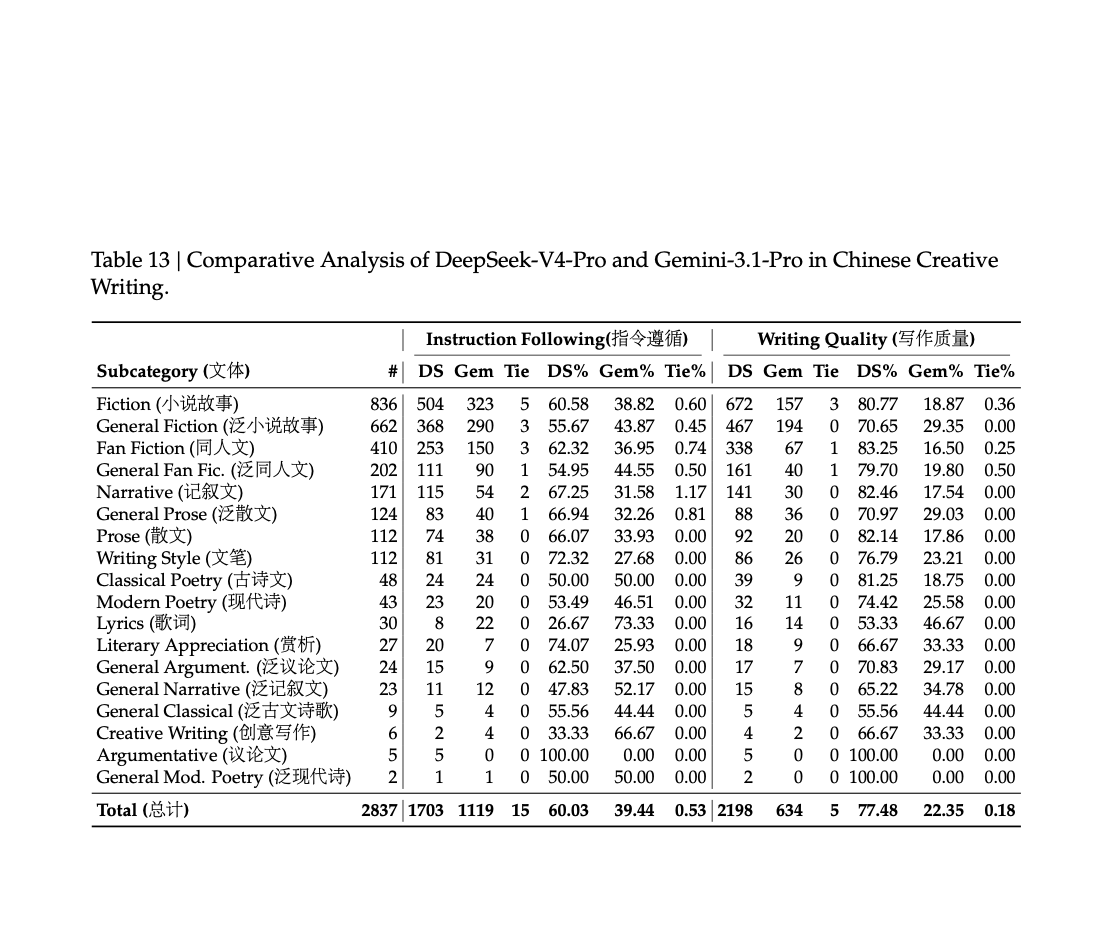
V4模型在中文写作和白领任务中表现良好,但在复杂任务上仍需提升。
-
V4通过改进注意力机制(hybrid attention)和优化器(Muon)来提高模型的训练稳定性和收敛速度。
-
模型采用了Compressed Sparse Attention (CSA)和Heavily Compressed Attention (HCA)来处理长上下文,显著降低了计算和缓存需求。
-
DeepSeek-V4的训练过程分阶段进行,逐步扩展序列长度,以确保模型在稳定条件下成长。
-
报告强调了系统层面的工程化设计,包括高性能kernel、并行处理和KV缓存管理,以支持1M上下文的训练和部署。
-
DeepSeek-V4在中文功能写作和白领任务中表现出色,但在复杂约束和多轮写作任务上仍有改进空间。
-
模型的评估结果显示,DeepSeek-V4在多个任务上超过了现有的开源模型,但在推理能力上与最前沿模型仍有差距。
延伸解读
超长上下文处理的挑战
DeepSeek-V4技术报告强调,处理超长上下文(如1M tokens)面临的主要挑战是计算和缓存成本。传统的注意力机制在处理长上下文时效率低下,因此,V4通过改进注意力机制和优化器,旨在降低这些成本,确保模型在实际应用中能够高效运行。
模型性能与实际应用
尽管DeepSeek-V4在中文写作和白领任务中表现出色,但在复杂任务上仍有提升空间。这表明,虽然模型在特定场景下表现良好,但在面对更复杂的约束和多轮写作时,仍需进一步优化以满足实际需求。
系统工程化设计的重要性
报告中提到的系统层面设计,如高性能kernel和KV缓存管理,显示出在训练和部署超长上下文模型时,工程化设计的重要性。这些设计不仅影响模型的性能,还决定了其在实际应用中的可行性和稳定性。
延伸问答
DeepSeek-V4的主要创新点是什么?
DeepSeek-V4通过改进注意力机制和优化器,提升了超长上下文处理效率,特别是支持1M tokens的上下文,同时降低了计算和缓存成本。
DeepSeek-V4在中文写作任务中的表现如何?
DeepSeek-V4在中文功能写作中表现出色,胜率达到62.7%,但在复杂约束和多轮写作任务上仍有改进空间。
DeepSeek-V4如何处理超长上下文的计算成本?
DeepSeek-V4采用Compressed Sparse Attention (CSA)和Heavily Compressed Attention (HCA)来降低计算和缓存需求,从而高效处理超长上下文。
DeepSeek-V4的训练过程是怎样的?
DeepSeek-V4的训练过程分阶段进行,逐步扩展序列长度,以确保模型在稳定条件下成长,先使用dense attention,再引入sparse attention。
DeepSeek-V4在复杂任务上的表现如何?
尽管DeepSeek-V4在中文写作和白领任务中表现良好,但在复杂任务上仍需进一步提升。
DeepSeek-V4的系统设计有哪些工程化特点?
DeepSeek-V4强调系统层面的工程化设计,包括高性能kernel、并行处理和KV缓存管理,以支持1M上下文的训练和部署。
