
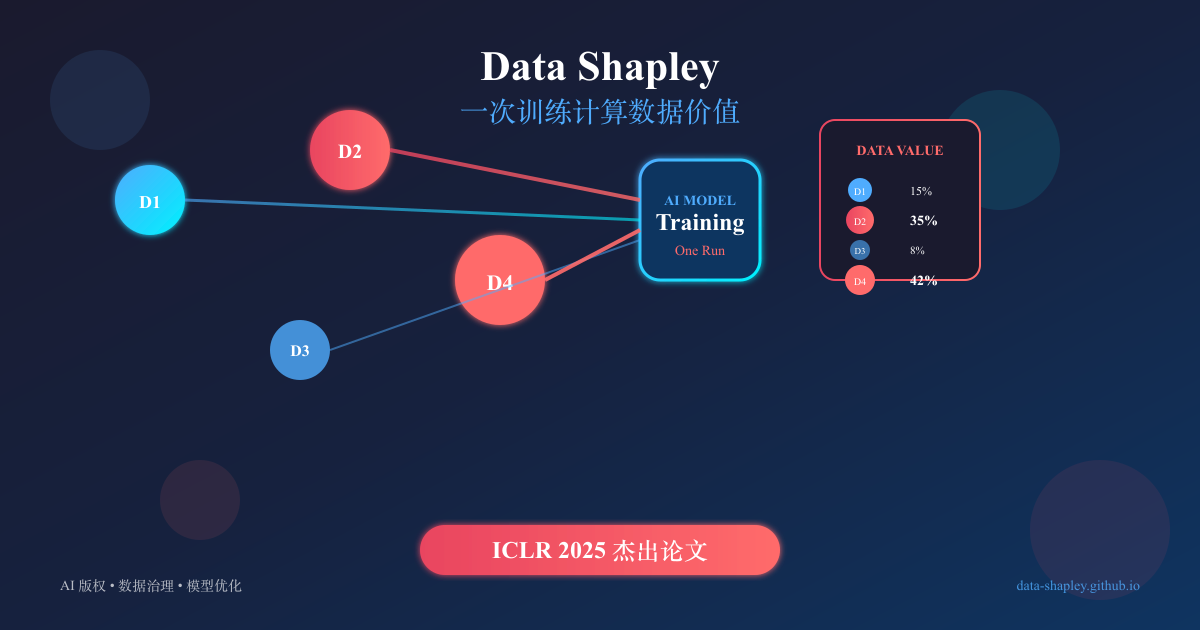
ICLR 2025 杰出论文:一次训练就能计算数据价值——AI 版权和数据治理的新突破
内容提要
本文提出了In-Run Data Shapley方法,实时追踪训练数据对模型的贡献,解决了传统方法计算复杂度高的问题。研究表明,数据价值在训练过程中会变化,精心策划的数据集可能仍包含负面数据,强调了数据治理的重要性。该方法为AI版权和数据质量提供了新视角,具有广泛的应用前景。
关键要点
-
提出了In-Run Data Shapley方法,实时追踪训练数据对模型的贡献。
-
解决了传统方法计算复杂度高的问题,适用于大规模模型。
-
数据价值在训练过程中会变化,强调数据治理的重要性。
-
即使是精心策划的数据集仍可能包含负面数据,需进行过滤。
-
该方法为AI版权和数据质量提供了新视角,具有广泛的应用前景。
-
实验结果显示训练数据对生成AI有贡献,可能改变版权评估方式。
-
识别和移除低质量数据,提高模型训练效率和质量。
-
未来可能影响AI版权诉讼、数据市场定价机制和模型训练透明度。
延伸解读
数据价值动态变化的启示
研究表明,训练过程中数据的价值会发生变化,尤其是在模型学习初期,通用数据的贡献可能较高,但随着训练的深入,其相关性会降低。这一发现提示我们在数据集构建时需考虑数据的动态特性,以便更好地优化模型性能。
数据治理的重要性
即使是经过精心策划的数据集,仍可能包含对模型训练产生负面影响的数据点。这强调了数据治理的必要性,研究者和开发者需要定期审查和清理数据集,以确保训练数据的质量,从而提高模型的整体表现和效率。
AI版权评估的新视角
In-Run Data Shapley方法为AI版权问题提供了新的技术解决方案,能够量化数据对模型的贡献。这一创新可能改变未来的版权评估方式,为数据创作者的权益保障提供了科学依据,推动数据市场的公平交易。
延伸问答
In-Run Data Shapley方法的核心思想是什么?
In-Run Data Shapley方法通过在单次训练过程中实时追踪每个数据点的影响,避免了传统方法的高计算复杂度。
这项研究如何影响AI版权评估?
研究提供了量化评估版权内容对AI模型贡献的技术基础,可能改变未来的版权评估方式。
数据价值在训练过程中是如何变化的?
数据价值在训练初期变化迅速,后期则趋于稳定,显示出专业数据的价值逐渐凸显。
为什么数据治理在AI训练中如此重要?
数据治理能够识别和移除低质量、有害数据,从而提高模型训练效率和质量,节省计算资源。
实验结果显示精心策划的数据集是否真的干净?
实验发现即使是精心策划的数据集,仍有约16%的数据点对训练过程产生负面影响。
In-Run Data Shapley方法的应用前景如何?
该方法具有广泛的应用前景,可能影响AI版权诉讼、数据市场定价机制和模型训练透明度。
