
内容提要
LongCat团队推出了新AI模型LongCat-Next,旨在统一处理图像、声音和文本等多模态信息。通过离散原生自回归架构DiNA和视觉分词器dNaViT,该模型实现了不同模态的统一建模,增强了理解与生成的协同能力。研究表明,离散化能更好地理解物理世界,且不损失信息。该模型已开源,欢迎开发者参与。
关键要点
-
LongCat团队推出了新AI模型LongCat-Next,旨在统一处理多模态信息。
-
模型通过离散原生自回归架构DiNA和视觉分词器dNaViT实现了不同模态的统一建模。
-
离散化能够更好地理解物理世界,且不损失信息。
-
LongCat-Next模型和离散分词器已开源,欢迎开发者参与。
-
DiNA架构将所有模态统一为离散Token,打破模态间的隔阂。
-
LongCat-Next实现了视觉理解与生成的对称性,理解与生成被统一为同一数学问题。
-
dNaViT技术将图像拆解为有意义的“视觉词汇”,支持任意分辨率的图像编码与解码。
-
SAE编码器通过视觉-语言监督学习高信息密度的表征,确保离散Token的语义完备性。
-
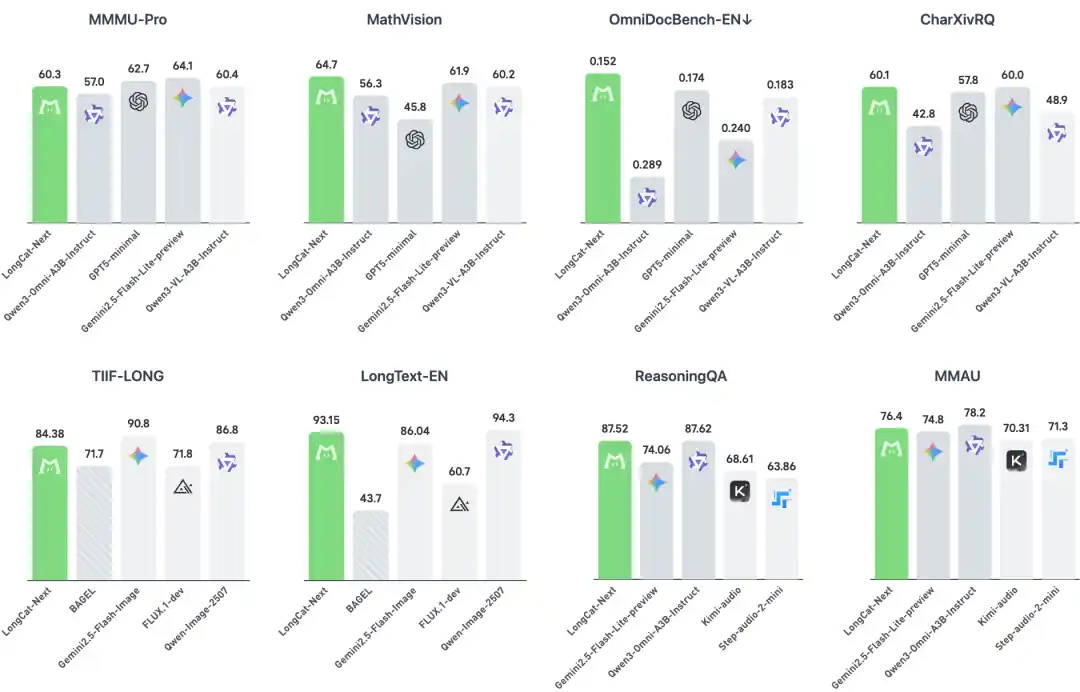
LongCat-Next在多个维度上展现出与多模专用模型相当甚至领先的性能。
-
模型在理解与生成上表现出协同潜力,理解没有损害生成,反而增强了性能。
-
LongCat-Next在文本任务和音频领域同样展现出良好的通用性,支持自然的语音交互。
-
LongCat-Next的开源为AI理解物理世界的多模态信号提供了新的视角。
延伸问答
LongCat-Next模型的主要目标是什么?
LongCat-Next模型旨在统一处理图像、声音和文本等多模态信息。
DiNA架构如何实现不同模态的统一建模?
DiNA架构通过将所有模态统一为离散Token,并用同一个自回归模型进行建模,打破了模态间的隔阂。
dNaViT技术的作用是什么?
dNaViT技术将图像拆解为有意义的“视觉词汇”,支持任意分辨率的图像编码与解码。
LongCat-Next在理解与生成方面的表现如何?
LongCat-Next在理解与生成上表现出协同潜力,理解没有损害生成,反而增强了性能。
LongCat-Next模型的开源对开发者有什么意义?
LongCat-Next的开源为AI理解物理世界的多模态信号提供了新的视角,欢迎开发者参与构建相关应用。
LongCat-Next在音频领域的表现如何?
LongCat-Next在音频领域展现出良好的通用性,支持低延迟的并行文本语音生成与可定制的语音克隆。
