
LISA(推理分割)笔记
内容提要
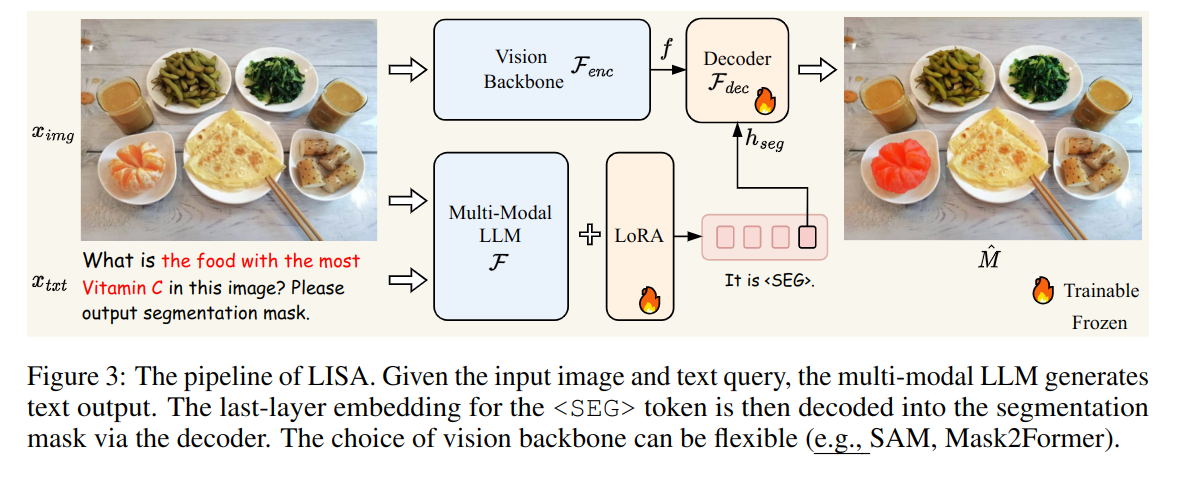
LISA(推理分割)是一种基于大型语言模型的语义分割新任务,通过图像和文本输入生成目标的分割掩码。论文提出了推理分割任务,建立了基准ReasonSeg,并训练了相应模型。LISA具备零样本能力,使用开源数据集进行训练,模型结构包括视觉编码器和解码器,训练目标为文本生成损失和分割掩码损失的加权和。
关键要点
-
LISA(推理分割)是一种新任务,通过图像和文本输入生成目标的分割掩码。
-
论文提出了推理分割任务,建立了基准ReasonSeg,并训练了相应模型。
-
LISA具备零样本能力,使用开源数据集进行训练。
-
模型结构包括视觉编码器和解码器,训练目标为文本生成损失和分割掩码损失的加权和。
-
训练数据由三部分组成,均为开源数据集,包括语义分割数据集、引用分割数据集和视觉问答数据集。
延伸解读
推理分割的创新性
LISA(推理分割)通过结合图像和文本输入,开创了一种新的语义分割任务。这种方法不仅提升了模型的灵活性,还能在没有特定训练数据的情况下进行推理,展现出其零样本能力。这一特性使得LISA在多模态学习领域具有重要的应用潜力,尤其是在需要快速适应新任务的场景中。
模型架构与训练目标
LISA的模型结构包括视觉编码器和解码器,训练目标是文本生成损失与分割掩码损失的加权和。这种设计使得模型能够有效地从图像中提取特征并生成准确的分割掩码。值得注意的是,训练过程中使用的开源数据集为模型的泛化能力提供了支持,尤其是在处理复杂的推理任务时。
训练数据的多样性
LISA的训练数据由三部分组成,涵盖了语义分割、引用分割和视觉问答等多个领域。这种多样性不仅增强了模型的适应性,还为其在不同应用场景中的表现提供了保障。研究者在选择数据集时应关注数据的代表性,以确保模型在实际应用中的有效性。
延伸问答
LISA(推理分割)是什么?
LISA是一种基于大型语言模型的语义分割新任务,通过图像和文本输入生成目标的分割掩码。
LISA的训练数据来源是什么?
LISA的训练数据由三部分组成,均为开源数据集,包括语义分割数据集、引用分割数据集和视觉问答数据集。
LISA具备哪些能力?
LISA具备零样本能力,可以在没有推理分割内容的训练集上进行推理分割。
LISA的模型结构是怎样的?
LISA的模型结构包括视觉编码器和解码器,使用文本生成损失和分割掩码损失的加权和作为训练目标。
LISA的训练目标是什么?
LISA的训练目标是文本生成损失和分割掩码损失的加权和,具体由λtxt和λmask确定。
LISA的应用场景有哪些?
LISA可以完成复杂推理、世界知识、解释性回答和多轮对话等任务。
