本研究提出了SegLLM,一种新型的多轮互动推理分割模型,通过对话记忆增强了大语言模型的分割能力。SegLLM在多轮任务中的性能提升超过20%,在单轮分割和定位任务中也有显著改善。
该研究提出了一种新的推理分割任务,展示了多模态语言模型LISA在复杂推理分割中的有效性。研究还介绍了开放词汇视频实例分割任务及其数据集,提出了VLP-RVOS框架以解决视频对象分割中的转移挑战,并开发了LLM-Seg框架,连接基础分割模型与大型语言模型,生成高质量的推理分割数据集LLM-Seg40K。
本文介绍了多模态大型语言模型(MLLM)在视觉与语言任务中的应用,重点讨论了MG-LLaVA和LLM-Seg框架,这些框架提升了目标识别和推理分割能力。同时,研究提出了新的数据集和方法,增强了模型的可解释性和感知能力,推动了相关领域的发展。
该研究提出了一种新的推理分割任务,展示了多模态语言模型LISA在复杂推理分割中的有效性。通过Chain-of-Spot方法,增强了视觉内容理解能力,并提出了两阶段训练框架以提升视觉推理性能和一致性。此外,开发了Visual CoT框架,结合可解释性推理处理复杂视觉输入,提供了有效的推理策略和数据集,推动相关研究进展。
该文介绍了一种保护边缘计算中输入和输出隐私的方法,即通过分割推理和 Salted DNNs 方法。该方法能够保持类似标准 DNN 的准确性和效率,并为未来研究提供了一个基准。
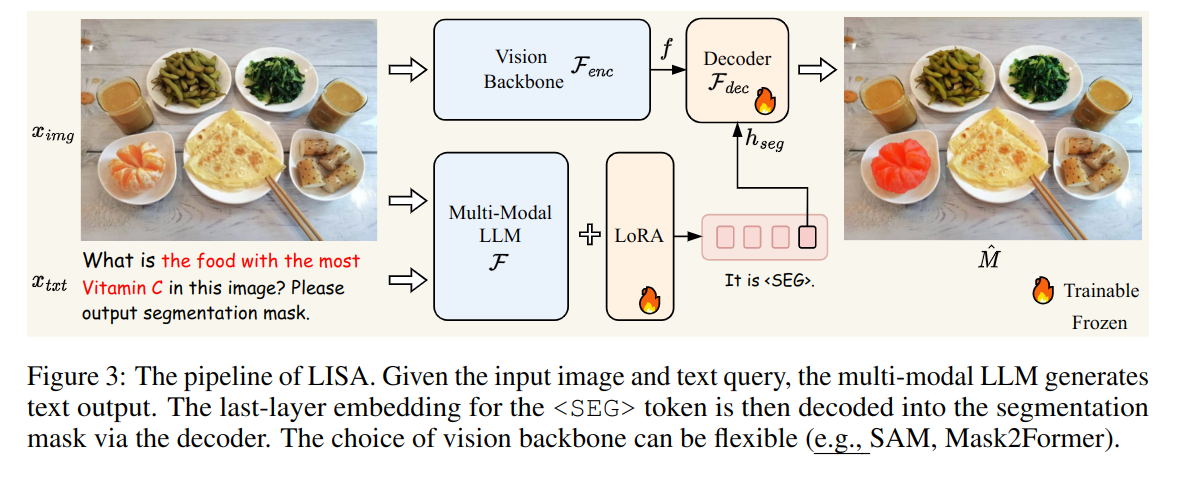
本文介绍了推理分割任务及其基准模型,通过大语言模型分割图像和文本。模型包括生成mask和视觉编码器,训练目标为文本生成损失和分割掩码损失的加权和。训练数据包括语义分割、引用分割和视觉问答数据集。作者还提到LISA具有zero-shot能力,需要训练的参数包括解码器、llm的词嵌入和投影最后一层的mlp。
LISA(推理分割)是一种基于大型语言模型的语义分割新任务,通过图像和文本输入生成目标的分割掩码。论文提出了推理分割任务,建立了基准ReasonSeg,并训练了相应模型。LISA具备零样本能力,使用开源数据集进行训练,模型结构包括视觉编码器和解码器,训练目标为文本生成损失和分割掩码损失的加权和。
完成下面两步后,将自动完成登录并继续当前操作。