
LISA(推理分割)笔记
原文中文,约1700字,阅读约需4分钟。
📝
内容提要
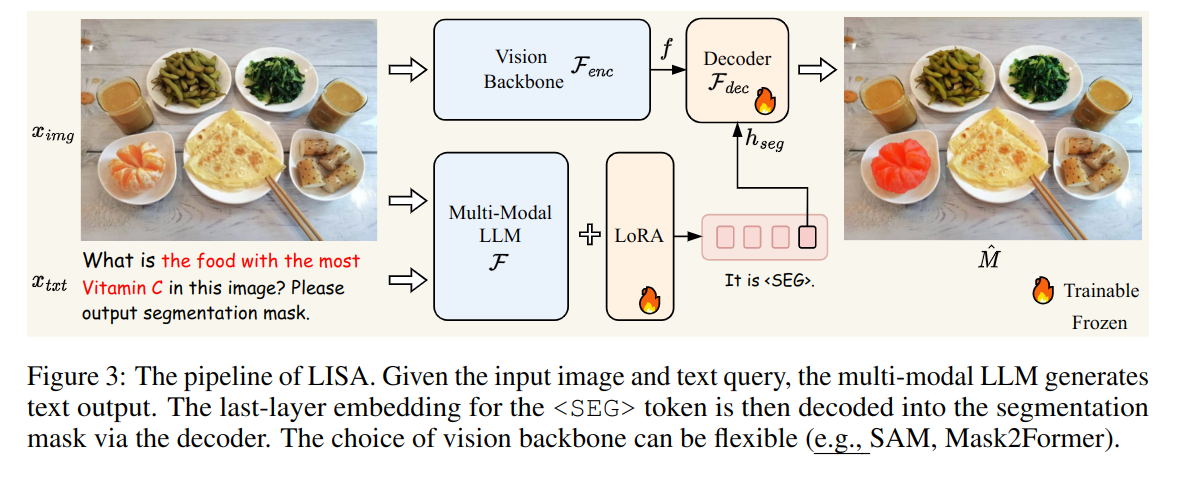
本文介绍了推理分割任务及其基准模型,通过大语言模型分割图像和文本。模型包括生成mask和视觉编码器,训练目标为文本生成损失和分割掩码损失的加权和。训练数据包括语义分割、引用分割和视觉问答数据集。作者还提到LISA具有zero-shot能力,需要训练的参数包括解码器、llm的词嵌入和投影最后一层的mlp。
🎯
关键要点
-
本文介绍了推理分割任务及其基准模型,利用大语言模型进行图像和文本的分割。
-
推理分割的任务是给定一张图和一段话,模型分割出目标物体。
-
作者提出了三个贡献:推理分割任务的提出、建立推理分割基准ReasonSeg、训练模型。
-
LISA可以完成四种任务:复杂推理、世界知识、解释性回答和多轮对话。
-
模型架构包括生成mask,使用大语言模型生成分割掩码。
-
训练LISA-7B只需10,000个训练步骤,使用8个NVIDIA 24G 3090 GPU。
-
训练目标是文本生成损失和分割掩码损失的加权和,进行端到端训练。
-
训练数据包括语义分割、引用分割和视觉问答数据集,均为开源数据集。
-
LISA具有zero-shot能力,训练集不包含推理分割内容。
-
需要训练的参数包括解码器、llm的词嵌入和投影最后一层的mlp。
🏷️
