
Kubernetes背后的反馈循环
内容提要
Kubernetes通过反馈控制机制有效管理大规模工作负载。文章探讨了如何手动运行Postgres数据库,并将其映射到Kubernetes的控制器模型。控制器通过观察当前状态与期望状态的差异,自动调整系统,确保高可用性和数据一致性,简化了操作过程。
关键要点
-
Kubernetes通过反馈控制机制有效管理大规模工作负载。
-
操作员是反馈控制器,负责调和期望状态与实际状态之间的差异。
-
手动运行Postgres数据库的过程展示了如何逐步建立反馈循环。
-
使用持久存储解决容器存储的短暂性问题,以确保数据的持久性。
-
高可用性需要多个Postgres实例及其之间的复制。
-
监控脚本用于自动修复数据库状态,确保系统的自我修复能力。
-
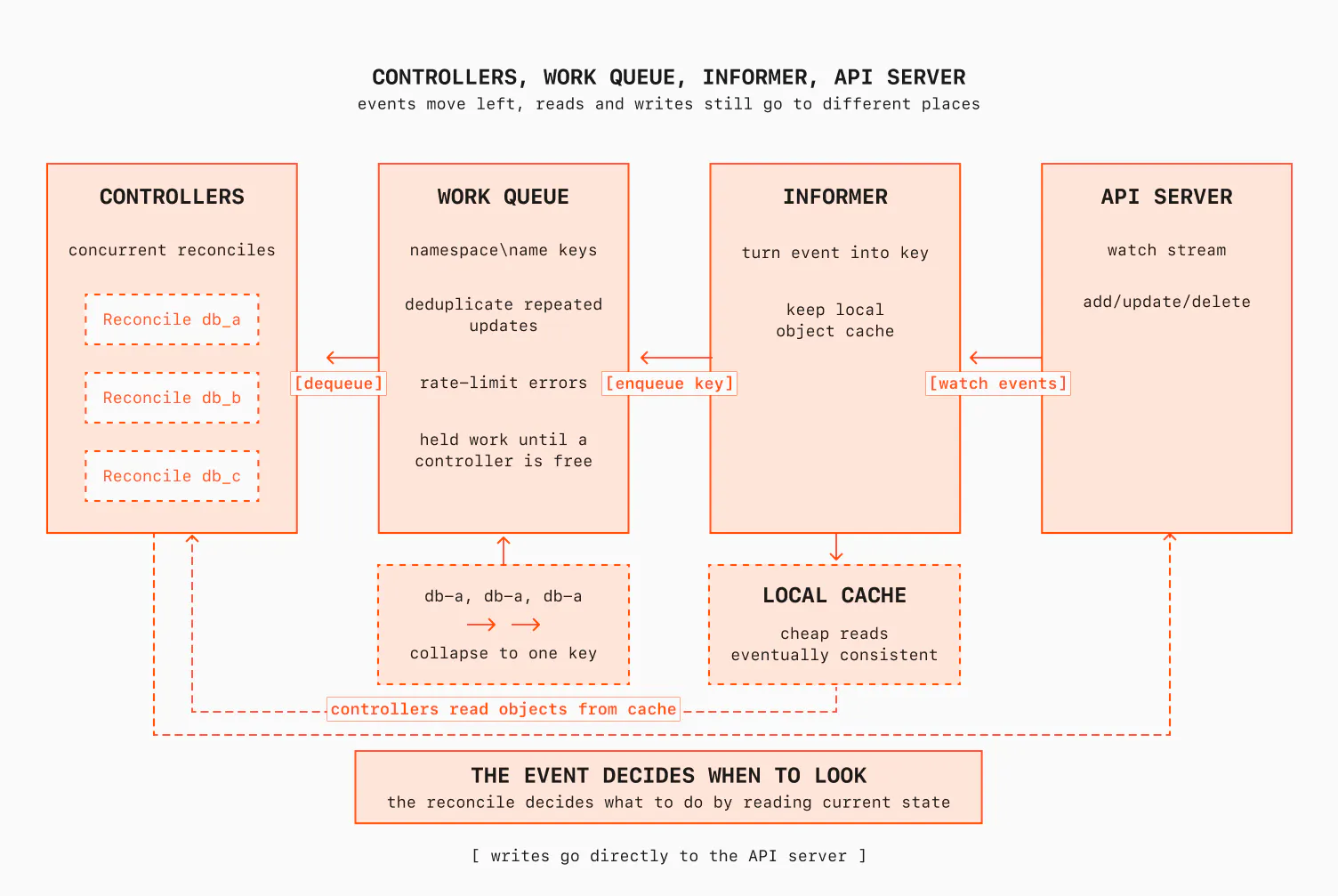
Kubernetes的控制器模型通过观察和调整系统状态来实现自动化管理。
-
Kubernetes的操作员通过控制循环实现对数据库的管理,确保系统的稳定性和一致性。
-
Kubernetes的设计允许多个控制器协同工作,形成级联控制系统。
-
Kubernetes不仅是容器运行时,更是一个反馈控制器框架,提供一致的状态存储和事件总线。
延伸解读
反馈控制的重要性
Kubernetes的反馈控制机制是其成功的关键。通过不断监测实际状态与期望状态之间的差异,Kubernetes能够自动调整系统,确保高可用性和数据一致性。这种机制不仅适用于数据库管理,也可以扩展到其他类型的工作负载,提升整体系统的稳定性和可靠性。
手动与自动化的对比
文章通过手动运行Postgres数据库的过程,展示了在没有Kubernetes的情况下,管理数据库的复杂性和潜在风险。手动操作容易导致错误和数据丢失,而Kubernetes的自动化控制则能有效减少人为干预,提高操作效率和数据安全性。
Kubernetes的设计优势
Kubernetes不仅是一个容器运行时,更是一个强大的反馈控制框架。其设计允许多个控制器协同工作,形成级联控制系统。这种架构使得Kubernetes能够处理复杂的状态管理任务,适应动态变化的环境,确保系统的自我修复能力。
延伸问答
Kubernetes如何管理大规模工作负载?
Kubernetes通过反馈控制机制,自动调整系统状态,确保高可用性和数据一致性,从而有效管理大规模工作负载。
什么是Kubernetes中的操作员?
操作员是Kubernetes中的反馈控制器,负责调和期望状态与实际状态之间的差异,确保系统的稳定性和一致性。
如何在Kubernetes中实现Postgres数据库的高可用性?
通过在多个节点上运行多个Postgres实例并进行数据复制,可以实现Postgres数据库的高可用性。
Kubernetes是如何确保数据持久性的?
Kubernetes使用持久存储解决容器存储的短暂性问题,以确保数据的持久性。
Kubernetes的控制器模型是如何工作的?
Kubernetes的控制器模型通过观察当前状态与期望状态的差异,自动调整系统,形成闭环反馈控制。
Kubernetes如何实现系统的自我修复能力?
Kubernetes通过监控脚本和反馈控制机制,自动修复数据库状态,确保系统的自我修复能力。
