
通过LLaMA代码分析,了解现代Transformer
原文中文,约16200字,阅读约需39分钟。
📝
内容提要
本文介绍了LLaMA模型的代码解析和实验结果,该模型是基于Transformer的语言模型,用于生成文本。文章详细解析了LLaMA的代码结构和特点,包括pre-normalization和Rotary Positional Embedding。同时,讨论了LLaMA在情感分析任务中的应用和使用score表示模型输出confidence的方法。最后,分析了Attention Weights的结果和未来的研究方向。
🎯
关键要点
-
本文介绍了LLaMA模型的代码解析和实验结果。
-
LLaMA是基于Transformer的decoder-only模型,没有encoder和cross attention。
-
LLaMA使用pre-normalization和Rotary Positional Embedding (RoPE)。
-
LLaMA的代码结构直观,主要分为Sampling和Model两部分。
-
Sampling方法包括beam search和temperature sampling,LLaMA使用后者。
-
LLaMA的模型参数包括dim=4096,n_layers=32,n_heads=32,vocab_size=32000。
-
LLaMA在情感分析任务中应用,使用补全任务提示模型。
-
模型输出的结果灵活,但缺乏confidence的表示。
-
通过log_softmax计算score来表示模型输出的confidence。
-
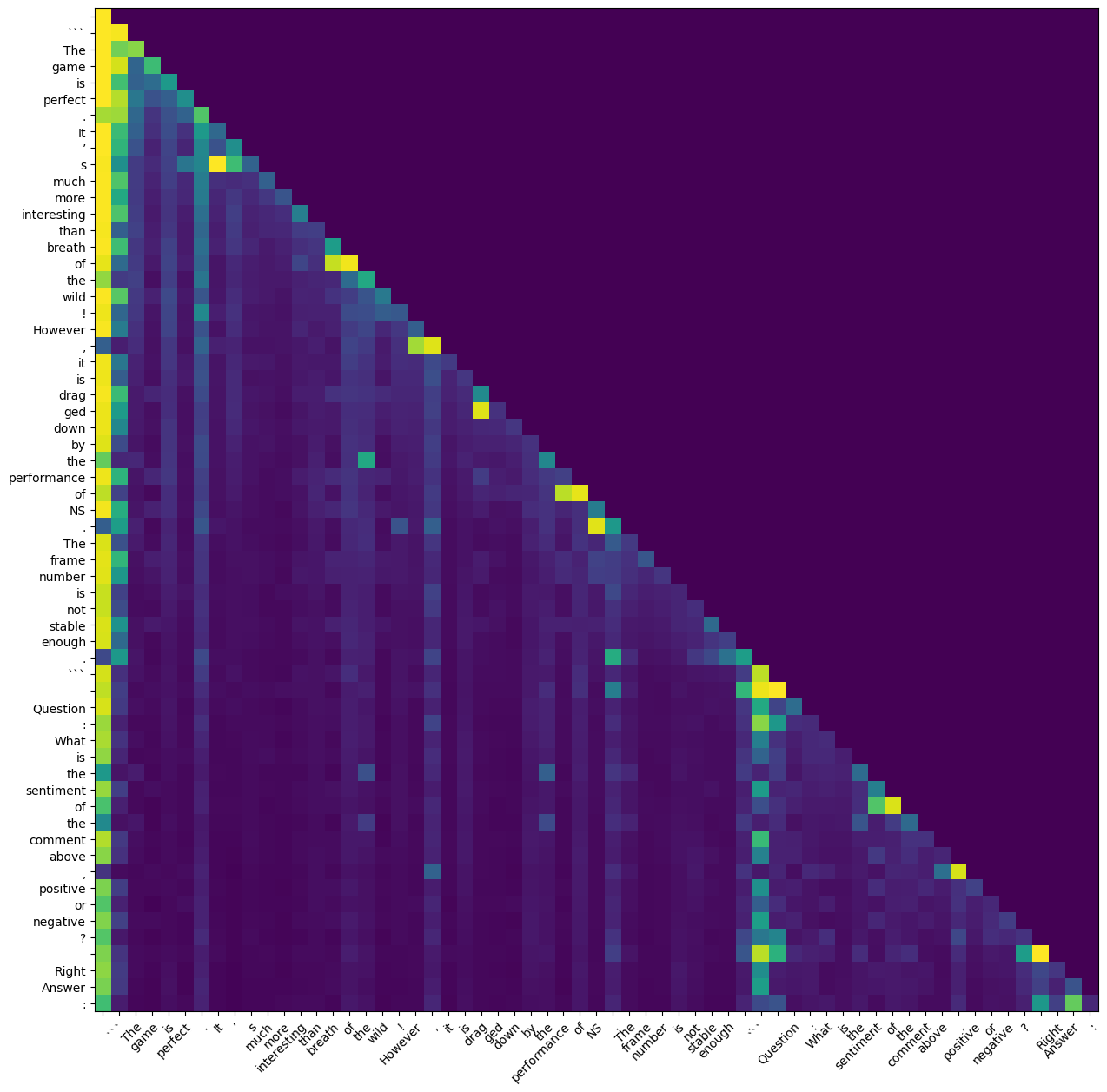
Attention Weights的分析显示模型对不同token的关注程度。
-
未来的研究方向包括训练部分的分析和小数据集的finetuning。
🏷️
