
Nextdoor的数据库演进:扩展阶梯
💡
原文英文,约2400词,阅读约需9分钟。
📝
内容提要
Nextdoor的数据库演进展示了系统设计的基本原则。最初使用单一PostgreSQL实例,随着用户增长,采用PgBouncer连接池解决连接瓶颈,随后引入主从架构应对读写冲突。通过动态路由和版本控制确保数据一致性,最终采用分片技术处理海量数据,体现了逐步复杂化的工程实践。
🎯
关键要点
- Nextdoor的数据库演进展示了系统设计的基本原则。
- 最初使用单一PostgreSQL实例,随着用户增长,采用PgBouncer连接池解决连接瓶颈。
- 引入主从架构应对读写冲突,确保数据一致性。
- 采用动态路由和版本控制,解决用户操作后的数据延迟问题。
- 实现高效的缓存层,使用Valkey和MessagePack减少内存占用。
- 建立版本控制和原子更新机制,确保缓存数据的准确性。
- 实施变更数据捕获(CDC)以处理潜在的错误和不一致。
- 最终采用分片技术处理海量数据,提升系统的可扩展性。
- Nextdoor的工程实践强调复杂性必须逐步获得,每一层解决一个问题的同时引入新的挑战。
❓
延伸问答
Nextdoor最初是如何管理其数据库的?
Nextdoor最初使用单一的PostgreSQL实例来处理所有的帖子、评论和社区更新。
Nextdoor是如何解决连接瓶颈问题的?
Nextdoor引入了PgBouncer作为连接池,允许多个应用程序工作者共享少量的数据库连接,从而解决了连接瓶颈问题。
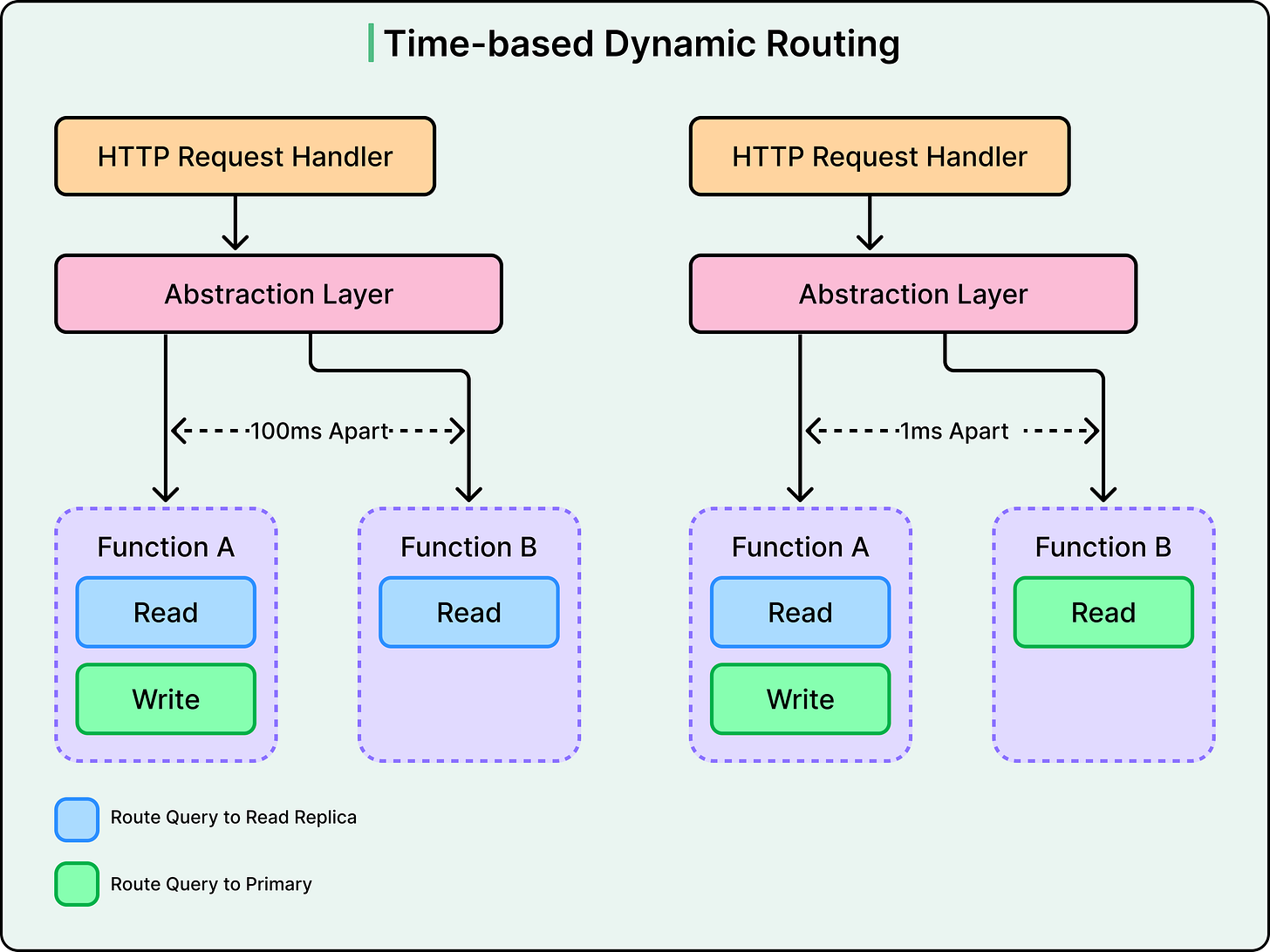
Nextdoor如何处理读写冲突?
Nextdoor采用主从架构,将写操作发送到主数据库,而读操作则路由到多个只读副本,从而减少了读写冲突。
Nextdoor是如何确保数据一致性的?
Nextdoor通过动态路由和版本控制来确保数据一致性,特别是在用户操作后,确保用户看到的总是最新的数据。
Nextdoor使用了什么技术来提高缓存效率?
Nextdoor使用Valkey作为高性能数据存储,并结合MessagePack进行数据压缩,以提高缓存效率。
Nextdoor在处理海量数据时采用了什么策略?
Nextdoor最终采用了分片技术,将数据分散到不同的数据库集群中,以处理海量数据并提升系统的可扩展性。
🏷️
标签
➡️
