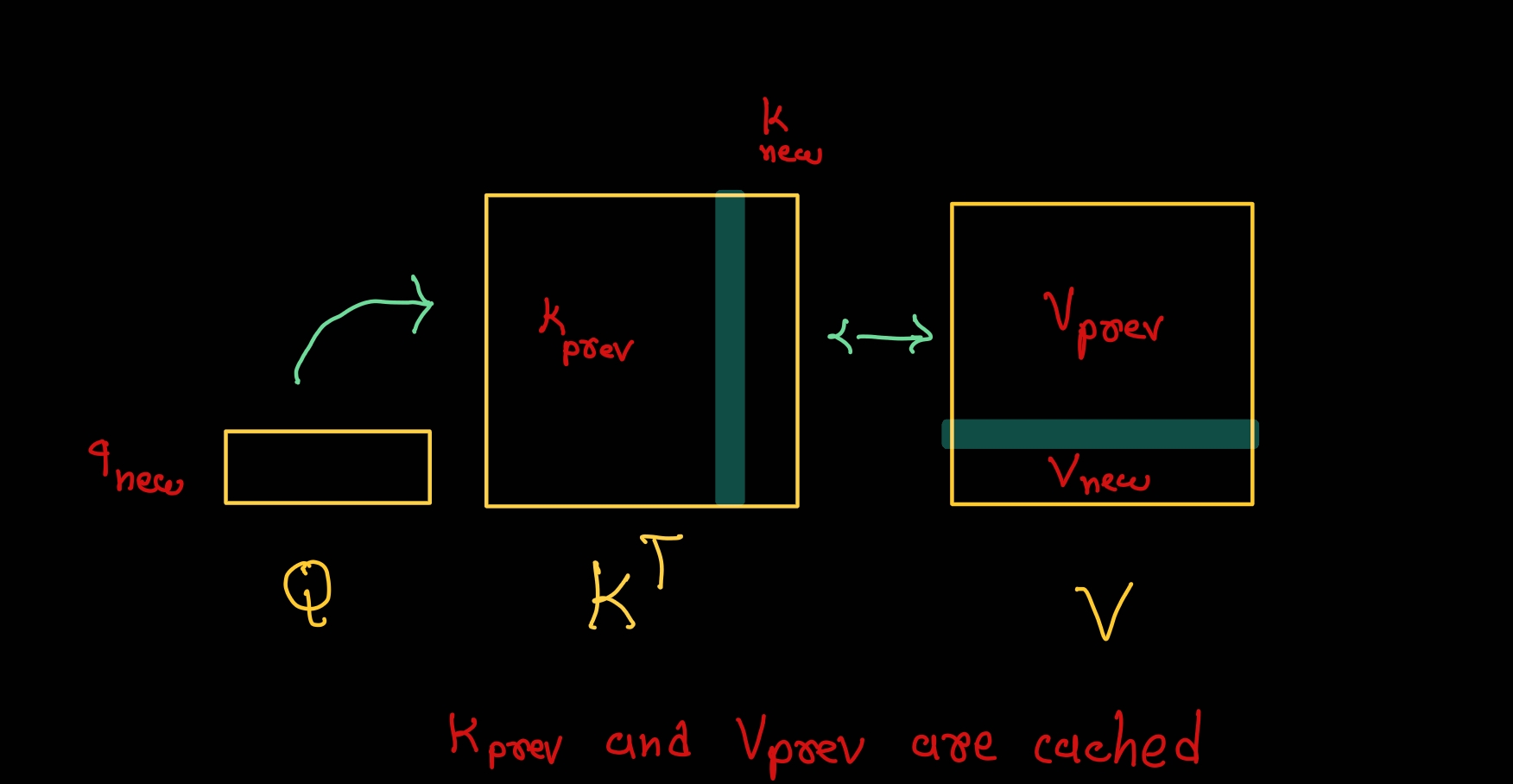
软通动力宣布“北京壹号词元工厂”正式投入运行
全球TMT-美通国际
·
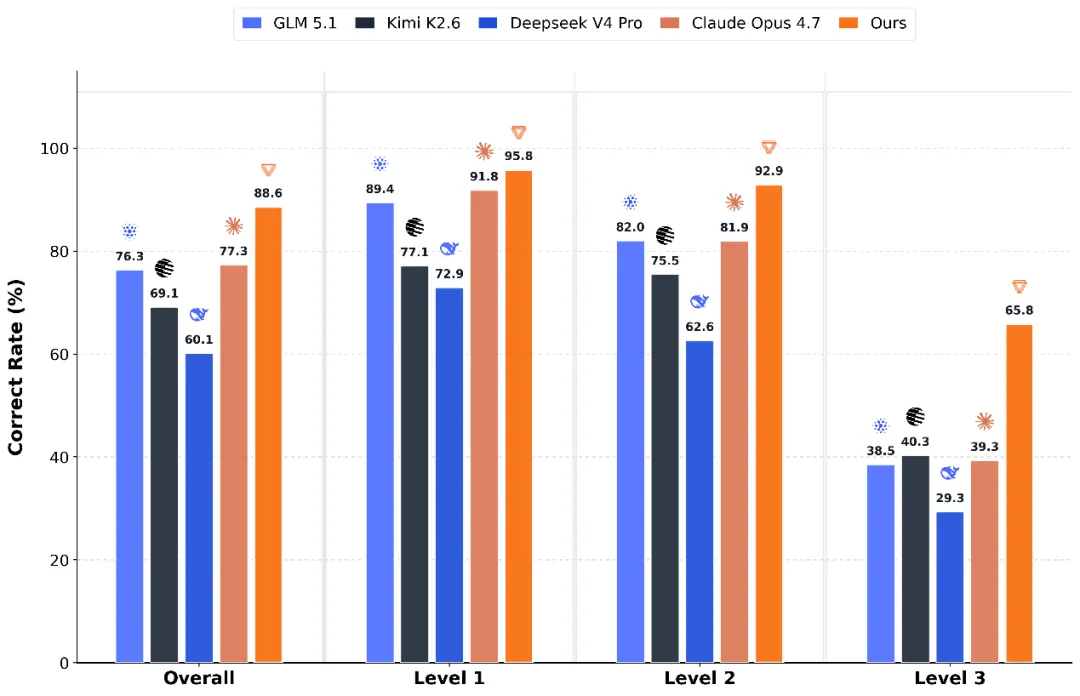

各家AI大模型API平台推荐与简介,2026.6.13更新
Zeruns's Blog
·

数颐联康上海老博会首发“南山大模型”
全球TMT-美通国际
·

斑马智能推出行业首个全模态端侧大模型AutoOmni
全球TMT-美通国际
·

关于适合什么模型,推荐下llmfit
Nicksxs's Blog
·



大模型企业扎堆IPO:智谱MiniMax冲刺A股,Anthropic抢先OpenAI递表
TechWeb 全站精华
·