
为什么主流大模型的上下文窗口都是128k?| 深度
内容提要
上下文工程是AI领域的新概念,强调大模型的上下文窗口的重要性。目前128k是主流标准,因其在处理长文本时效率高,满足多种应用需求。尽管有向百万上下文扩展的尝试,但技术和成本限制使128k仍为最广泛应用的长度。未来将关注信息利用效率,以实现更智能的AI模型。
关键要点
-
上下文工程是AI领域的新概念,强调大模型的上下文窗口的重要性。
-
128k是主流标准,因其在处理长文本时效率高,满足多种应用需求。
-
尽管有向百万上下文扩展的尝试,但技术和成本限制使128k仍为最广泛应用的长度。
-
上下文是大模型研究的核心问题,越大的上下文窗口使模型更聪明、连贯。
-
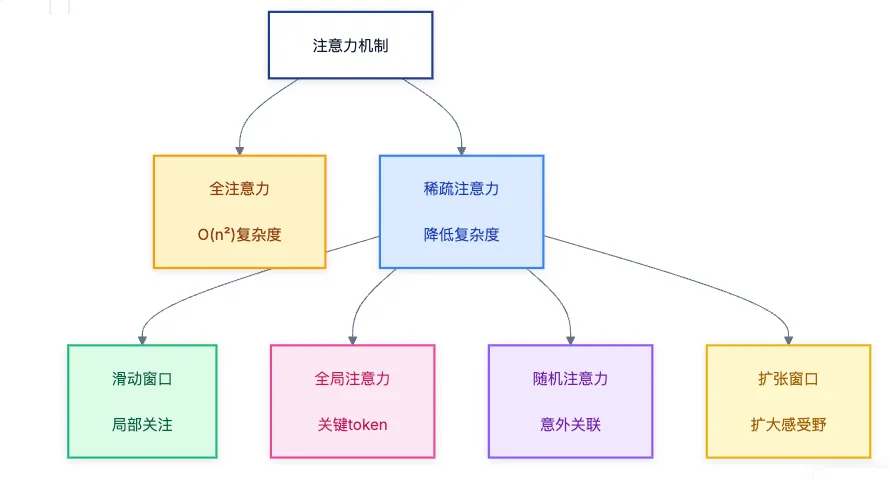
Transformer架构的自注意力机制解决了传统RNN模型的上下文窗口局限性。
-
128k上下文窗口的计算和内存需求大幅增加,给GPU带来挑战。
-
128k上下文已能满足法律、科研、企业数据分析等多种实际场景的需求。
-
并非所有应用都需要长上下文,简单任务可用较小的上下文窗口。
-
长文本上下文能力的提升是模型架构、注意力机制、训练策略等多方面协同创新的结果。
-
未来的竞争焦点将转向信息利用效率,目标是实现通用人工智能的愿景。
延伸解读
上下文窗口的重要性
上下文窗口是大模型的“记忆”,其大小直接影响模型的智能和连贯性。128k的上下文窗口能够有效处理长文本,满足法律、科研等领域的需求,提升了模型在复杂任务中的表现。
技术与成本的博弈
尽管有向百万上下文扩展的尝试,但128k仍是主流选择,主要是因为更大上下文窗口带来的计算和内存需求显著增加,给GPU带来挑战。技术的进步与成本的限制形成了微妙的平衡。
应用场景的多样性
128k上下文窗口已能满足多种实际应用,如法律文档分析和复杂对话系统。然而,并非所有任务都需要如此长的上下文,简单任务使用较小窗口反而更为高效,避免不必要的计算开销。
延伸问答
上下文窗口的大小对大模型有什么影响?
上下文窗口越大,模型能记住的内容就越多,从而变得更聪明和连贯。
为什么128k成为主流的上下文窗口标准?
128k在处理长文本时效率高,满足多种应用需求,同时技术和成本限制使其成为最广泛应用的长度。
长上下文窗口的计算和内存需求如何影响GPU?
128k上下文窗口的计算和内存需求大幅增加,可能需要多张GPU并行计算,增加系统复杂性。
哪些技术推动了上下文窗口的扩展?
模型架构的演进、注意力机制的优化以及工程层面的创新共同推动了上下文窗口的扩展。
128k上下文窗口适合哪些应用场景?
128k上下文窗口适合法律、科研、企业数据分析等需要处理长文档的场景。
未来上下文窗口的发展趋势是什么?
未来将关注信息利用效率,目标是实现更智能的AI模型,可能会探索更大的上下文窗口。
