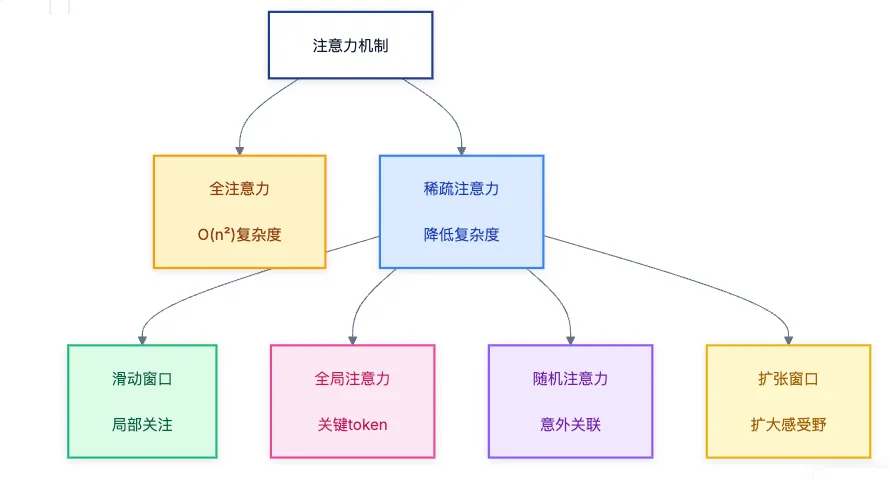
英伟达与多所高校合作推出TTT-E2E方法,能将128K上下文处理速度提升2.7倍,动态压缩记忆,避免额外缓存。该技术基于标准Transformer,支持持续学习,适应测试需求。尽管在细节回忆任务中表现不如全注意力模型,但推理延迟稳定,生成文本质量高。
上下文工程是AI领域的新概念,强调大模型的上下文窗口的重要性。目前128k是主流标准,因其在处理长文本时效率高,满足多种应用需求。尽管有向百万上下文扩展的尝试,但技术和成本限制使128k仍为最广泛应用的长度。未来将关注信息利用效率,以实现更智能的AI模型。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,简化数据爬取流程。
本文介绍了一系列支持高达32,768个令牌的长上下文语言模型(LLMs),通过持续预训练,这些模型在长文本任务上相较于Llama 2取得显著提升。研究表明,适当的数据混合和持续预训练策略能有效扩展上下文长度至128K,并在长上下文理解方面表现优异。实验结果显示,商业模型在短依赖任务上优于开源模型,但在长依赖任务上仍面临挑战。
完成下面两步后,将自动完成登录并继续当前操作。