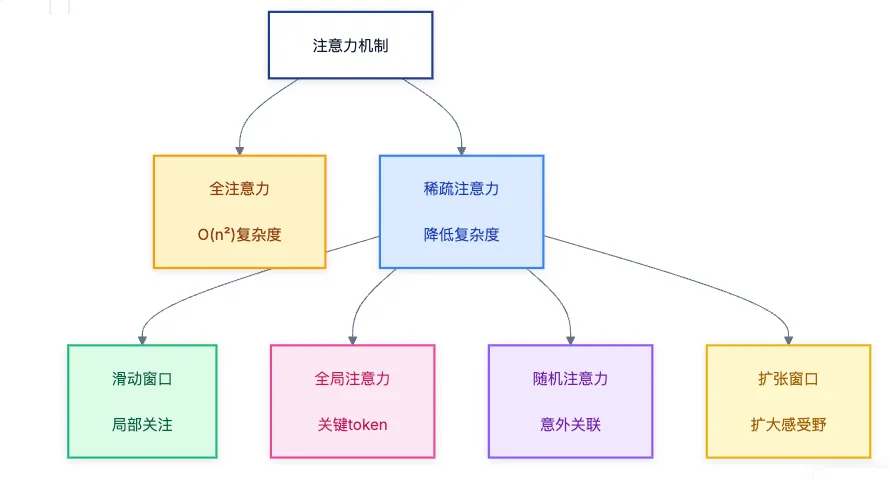
美团龙猫LongCat推出新稀疏注意力机制LoZA,解码速度提升10倍,支持处理1M长文本。通过优化模型结构,降低计算复杂度,提高效率,同时保持稳定性能。该技术在长文本任务中优于同类模型,未来将支持动态稀疏比例,以适应不同场景需求。
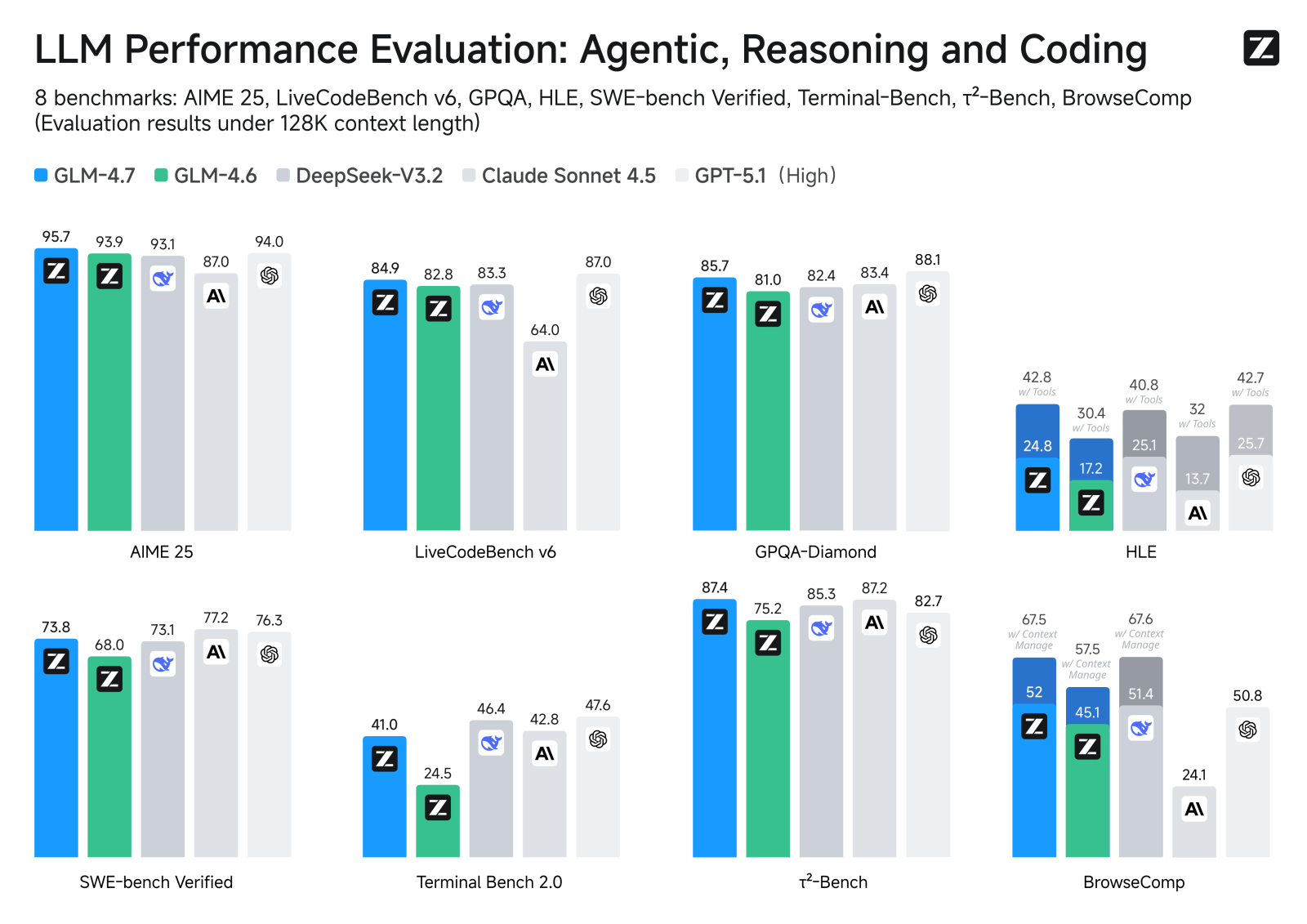
智谱AI开源了旗舰模型GLM-4.7,支持百万级长文本,增强代码生成能力,并在逻辑推理和多模态理解上表现优异。开发者可通过HuggingFace平台下载或调用API。
中国联通研究团队在AAAI 2026上发布了HiMo-CLIP模型,解决了长文本图像检索中的语义层级和单调性问题。该模型通过动态特征提取和对齐机制,显著提高了长短文本的检索精度,性能优于现有模型。
DeepSeek新模型DeepSeek-OCR通过视觉压缩文本,显著提升了长文本处理效率。在OmniDocBench基准测试中,压缩率小于10倍时准确率达到97%。研究者提出的“上下文光学压缩”方法模拟人类记忆机制,可能为AGI提供新思路。
DeepSeek-V3.2-Exp模型现已支持,采用稀疏注意力机制,适用于长文本任务。vLLM集成了新的CUDA内核,优化了性能,用户可通过特定指令进行部署和测试,未来将扩展对更多硬件的支持。
GPT-5发布后引发热议,Youtuber Berman展示其在魔方、网页Word、Excel等任务中的表现。尽管表现出色,但也遭到质疑,尤其是马斯克认为其不如Grok 4。GPT-5在多模态能力和长文本处理上有显著提升,但仍存在一些问题。
DeepSeek的梁文锋团队在ACL 2025获得最佳论文奖,提出了原生稀疏注意力(NSA)机制,处理长文本的速度提升了11倍,性能超越传统模型。NSA通过动态分层策略优化计算,显著提高推理和训练效率,尤其在复杂推理任务中表现突出。
本文探讨了通过增强AI标注系统提升长文本、数学和代码任务反馈质量的方法。我们提出了一种代理系统,利用网络搜索和代码执行验证标注,减少LLM内部偏见的影响。实验结果表明,该方法在多个任务领域表现良好,并提供了开源代码以供复现。
研究发现,长文本输入(超过1万tokens)会显著降低大型语言模型(LLM)的性能,准确率从90%降至50%。不同模型在处理长文本时表现差异,输入内容的语义特征和结构也会影响性能衰减。实验揭示了模型在长上下文任务中的局限性,建议优化指令和保存上下文以提升性能。
上下文工程是AI领域的新概念,强调大模型的上下文窗口的重要性。目前128k是主流标准,因其在处理长文本时效率高,满足多种应用需求。尽管有向百万上下文扩展的尝试,但技术和成本限制使128k仍为最广泛应用的长度。未来将关注信息利用效率,以实现更智能的AI模型。
该研究提出了细粒度CLIP(FG-CLIP),通过生成16亿对长文本与图像,增强了模型对细微语义差异的识别能力。实验结果表明,FG-CLIP在多个任务中超越了原始CLIP及其他方法,有效提升了模型性能。
OpenAI推出了GPT-4.1系列模型,包括标准版、迷你版和纳米版,支持高达100万个上下文标记,提升了长文本理解能力。与Claude 3.7 Sonnet和Gemini 2.5 Pro相比,GPT-4.1在编码和指令执行方面表现优异,但在某些任务上仍需改进。
本研究提出FineLIP方法,解决CLIP模型在处理长文本时的局限性,通过细粒度对齐实现文本与图像的跨模态映射,实验结果表明其在长文本检索和生成任务中优于现有方法。
北京大学提出的LIFT框架通过将长文本知识存储在模型参数中,提升了大语言模型对长文本的理解能力。LIFT动态调整模型参数,降低了传统方法的复杂度和存储开销,显著提高了长文本任务的表现。实验结果表明,LIFT在多个基准测试中有效提升了模型准确率,展现出良好的应用前景。
本研究回顾了大型语言模型在处理长文本时性能下降的问题,提出了四种解决方法:位置编码、上下文压缩、检索增强和注意力模式,并强调了长文本的评估及未来发展方向。
随着大模型在长文本处理中的应用增多,传统的困惑度评估方法显现出局限性。研究表明,某些模型在困惑度上表现良好,但实际效果不佳。北京大学团队提出了新的评估指标长文本困惑度(LongPPL),更准确地反映模型在长文本处理中的能力,并提出长文本交叉熵(LongCE)以优化训练效果。
2025年2月,AI研究团队发布了NoLiMA论文,提出了评估大语言模型处理长文本的新基准。研究揭示了现有模型在长上下文中依赖表面匹配的局限性,并强调了语义推理能力的快速下降。此外,研究还探讨了嵌入模型在不同上下文长度下的表现,发现即使使用查询扩展,性能仍显著下降。
本研究提出了一种新的服从-sympow变压器,旨在解决传统对称幂变压器在处理长文本时的信息保留不足问题。通过数据依赖的乘法门控和自适应旋转嵌入技术,该方法能够动态释放和存储容量,初步实验显示其在训练和评估中表现优异,有效克服了对称幂变压器的局限性。
华为诺亚方舟实验室发布的新ESA算法通过稀疏注意力设计,突破了大模型在长文本处理中的瓶颈,显著提升了计算效率和性能。ESA通过低维压缩和动态选择关键token,降低了计算复杂度,适用于长序列任务,实验结果显示其在多项基准测试中优于传统方法。
飞桨PP-UIE是一个支持中英文的信息抽取大模型,具备强大的零样本和小样本学习能力,能够高效处理长文本,适用于多种应用场景。
完成下面两步后,将自动完成登录并继续当前操作。