
智谱宣布开源旗舰模型GLM-4.7 对训练数据进行大规模清洗提升代码生成能力
内容提要
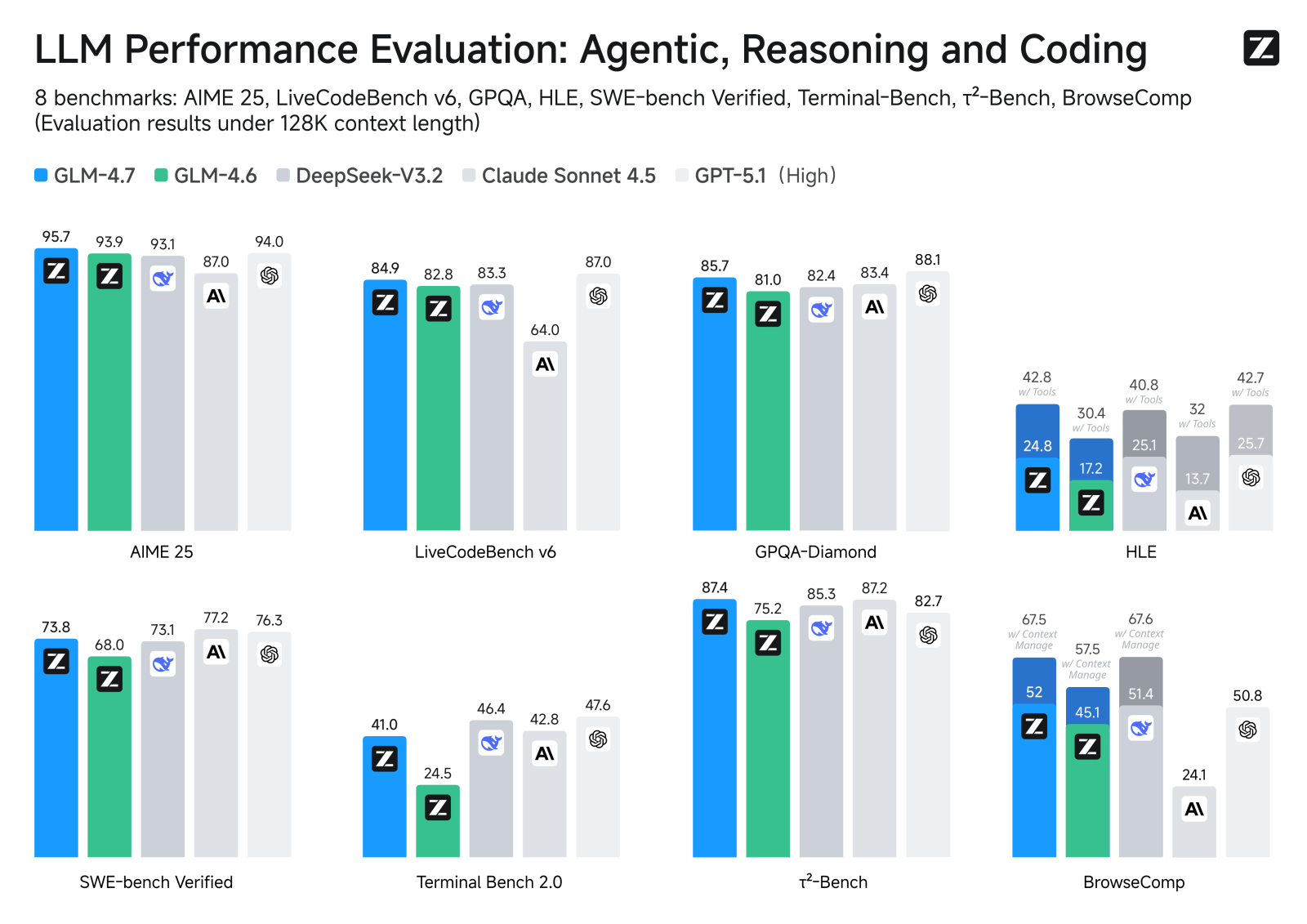
智谱AI开源了旗舰模型GLM-4.7,支持百万级长文本,增强代码生成能力,并在逻辑推理和多模态理解上表现优异。开发者可通过HuggingFace平台下载或调用API。
关键要点
-
智谱AI开源旗舰模型GLM-4.7,支持百万级长文本。
-
模型经过大规模清洗和扩充,显著提升代码生成能力。
-
GLM-4.7在逻辑推理、超长上下文处理和多模态理解方面表现优异。
-
支持最高100万个Token的超长上下文,简化海量数据处理。
-
原生支持图像和文档等多种模态的直接理解。
-
增强代码生成、调试和高等数学问题的解决能力。
-
采用灵活的参数架构,适应不同硬件环境的部署。
-
经过RLHF训练,GLM-4.7对指令的遵循能力强。
-
遵循开源协议,允许开发者进行二次开发。
-
开发者可通过HuggingFace平台下载或调用API。
延伸解读
模型的多模态理解能力
GLM-4.7不仅支持文本处理,还具备对图像和文档的原生理解能力。这意味着开发者可以在更广泛的应用场景中使用该模型,尤其是在需要结合多种数据类型进行深层次推理的任务中,提升了模型的实用性和灵活性。
超长上下文处理的优势
GLM-4.7支持最高100万个Token的超长上下文,这一特性使得模型在处理复杂任务时能够更好地理解和整合大量信息,减少了信息丢失的风险。开发者在设计应用时应考虑如何利用这一优势来优化用户体验。
开源与灵活部署的潜力
智谱AI的开源策略为开发者提供了灵活的部署选择,适应不同硬件环境的需求。通过提供多种规模的权重文件,开发者可以根据自身的显存限制进行选择,这为中小型企业和个人开发者降低了使用门槛。
延伸问答
GLM-4.7模型的主要特点是什么?
GLM-4.7支持百万级长文本,经过大规模清洗和扩充,显著提升代码生成能力,并在逻辑推理和多模态理解上表现优异。
开发者如何获取GLM-4.7模型?
开发者可以通过HuggingFace平台下载GLM-4.7模型或调用智谱提供的API进行接入。
GLM-4.7在处理复杂任务时有什么优势?
GLM-4.7在逻辑推理、超长上下文处理和多模态理解方面表现优异,能够更好地处理复杂任务和海量信息。
GLM-4.7支持哪些类型的数据处理?
GLM-4.7支持文本、图像和文档等多种模态的直接理解,能够结合上下文进行深层次的推理。
GLM-4.7的开源协议是什么?
GLM-4.7遵循相关开源协议,允许开发者进行使用和二次开发。
GLM-4.7如何提升代码生成能力?
GLM-4.7通过对训练数据集进行大规模清洗和扩充,特别增强了代码生成、调试和高等数学问题的解决能力。
