
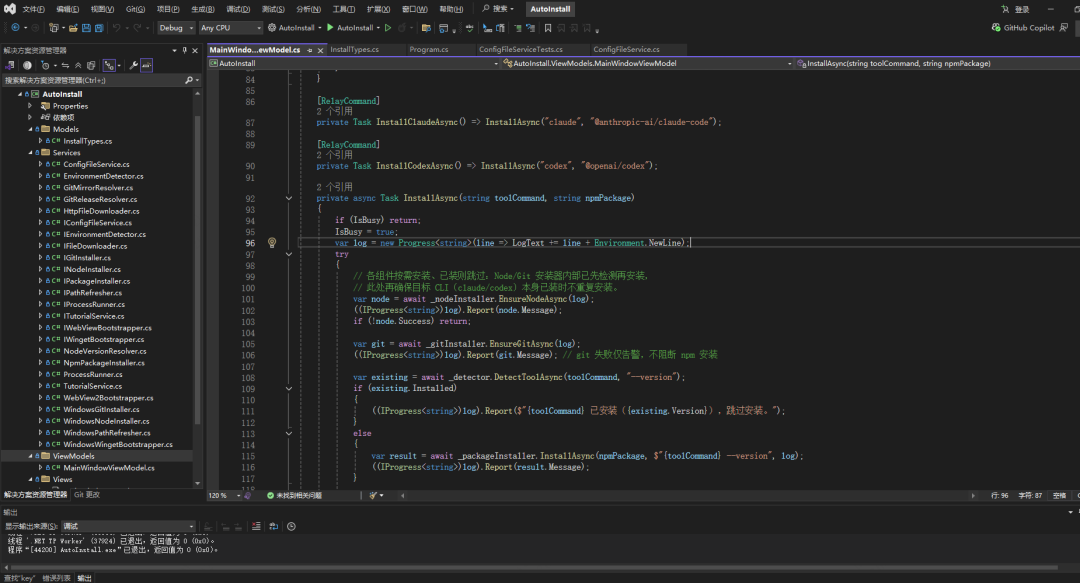
Claude Code / Codex 一键安装器 (附带C#源码,MIT开源)
dotNET跨平台
·
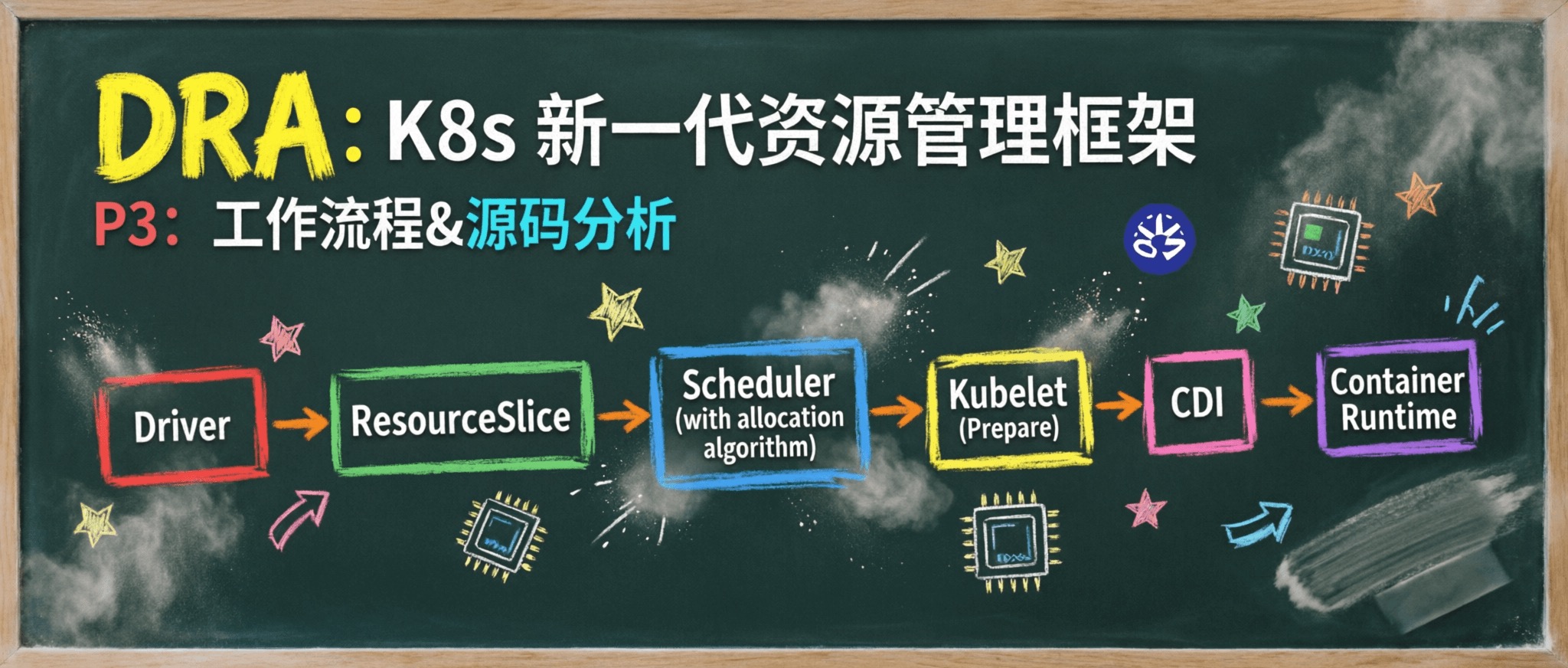
DRA P3:DRA 工作流程与源码分析
探索云原生
·
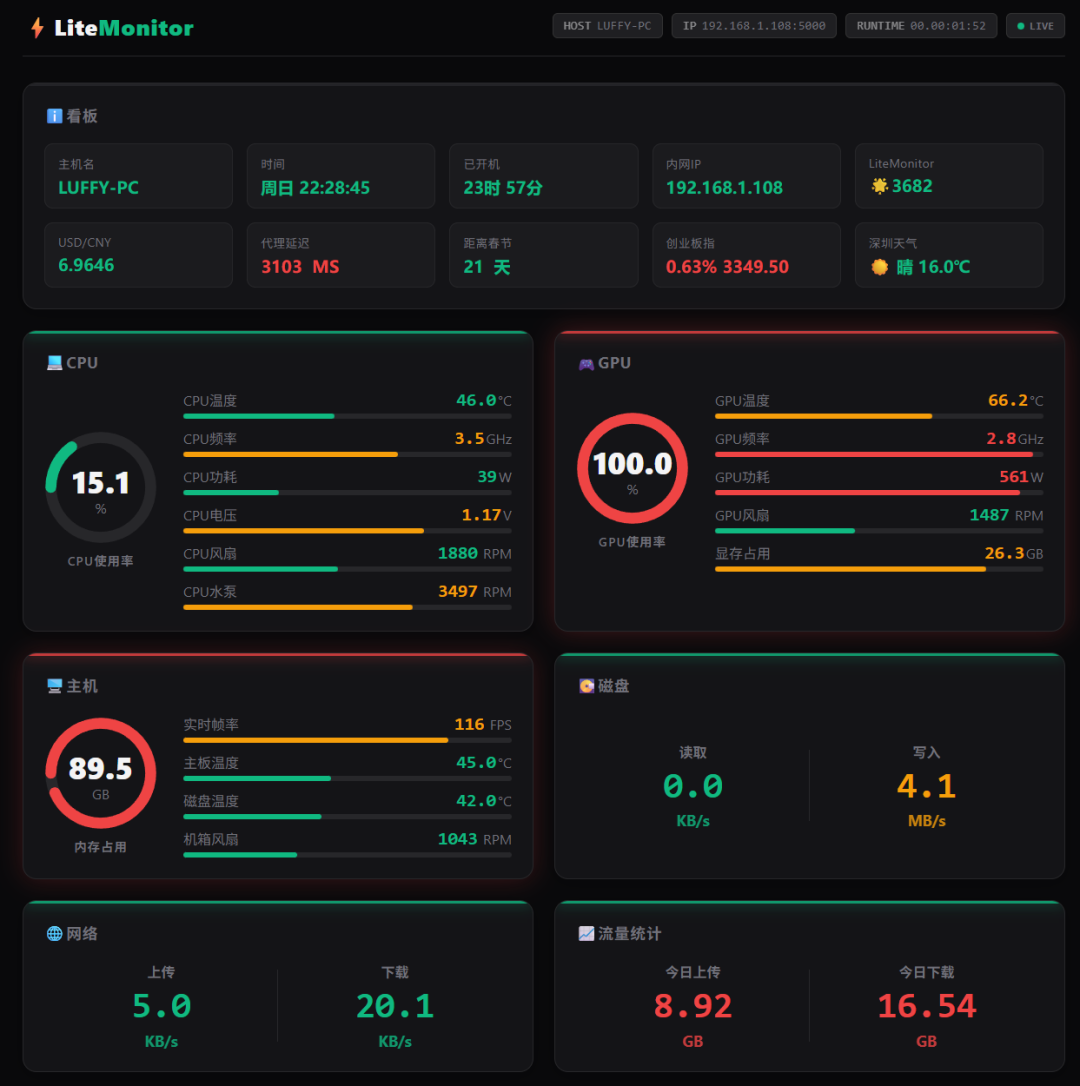
源码开源可控!基于.NET8开发的轻量 Windows 监控工具 在IoT 边缘服务器落地实践
dotNET跨平台
·
