

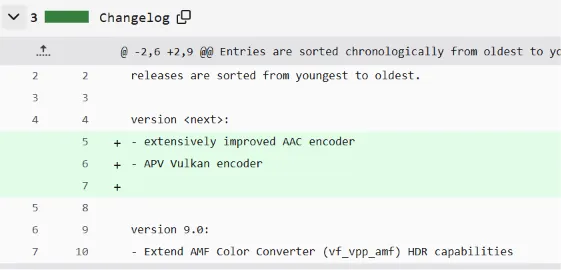
FFmpeg 推出 Vulkan APV 编码器
实时互动网
·
OLAP – 第三阶段压缩
Kimserey Lam’s website, Software Development blog posts, videos and tutorials
·

赛事直播低延迟推流:从采集到分发的关键配置
实时互动网
·

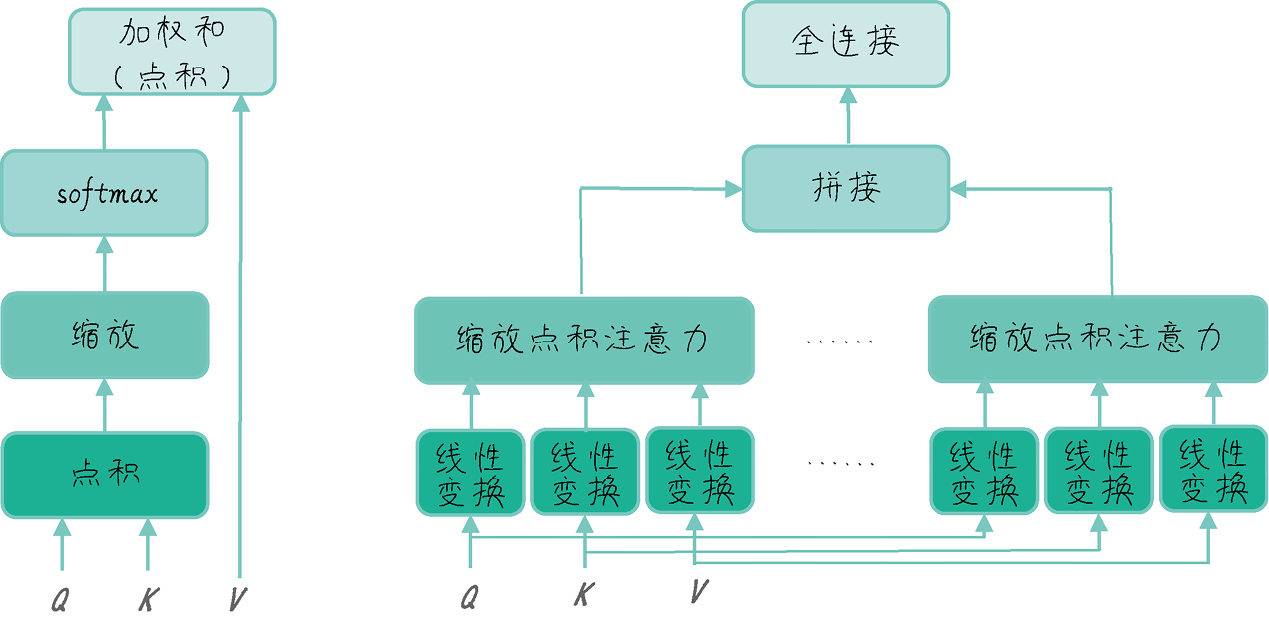
《GPT 图解》笔记:Transformer
Ying’s Blog
·

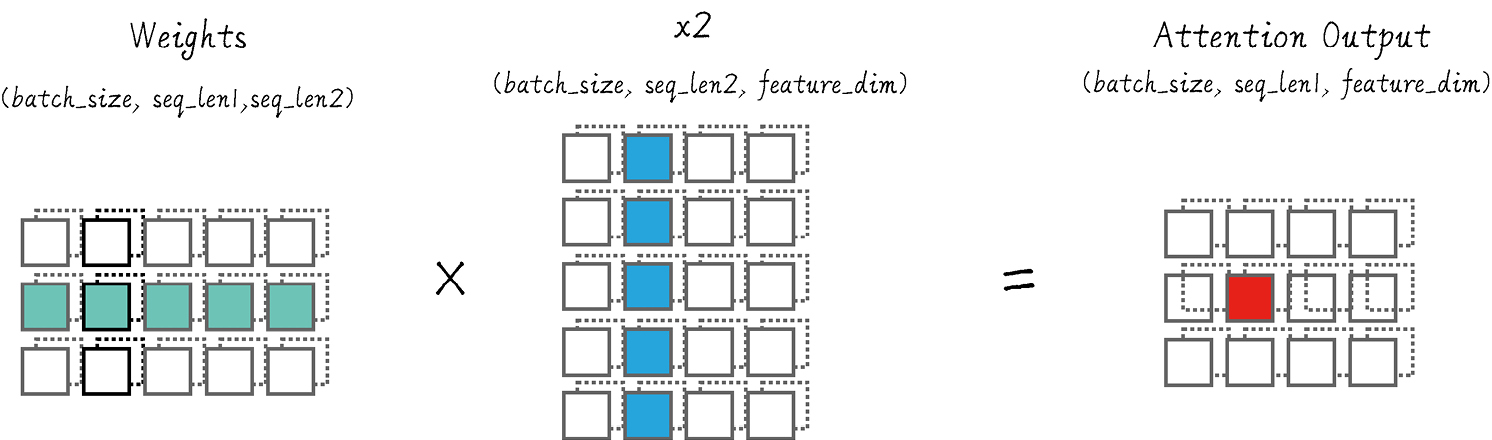
《GPT 图解》笔记:Seq2Seq及点积注意力
Ying’s Blog
·

实用学习型图像压缩中的关键因素
Apple Machine Learning Research
·


极海推出G32R430在轴多摩川协议磁电式编码器参考方案
全球TMT-美通国际
·


