人工智能论文评审:语言模型是少量学习者(GPT-3)
freeCodeCamp.org
·

何恺明首个语言模型:不走GPT老路,105M参数干翻主流
dotNET跨平台
·

人工智能论文评审:语言模型是无监督的多任务学习者(GPT-2)
freeCodeCamp.org
·

BalCapRL:一种基于强化学习的多模态大语言模型图像描述的平衡框架
Apple Machine Learning Research
·
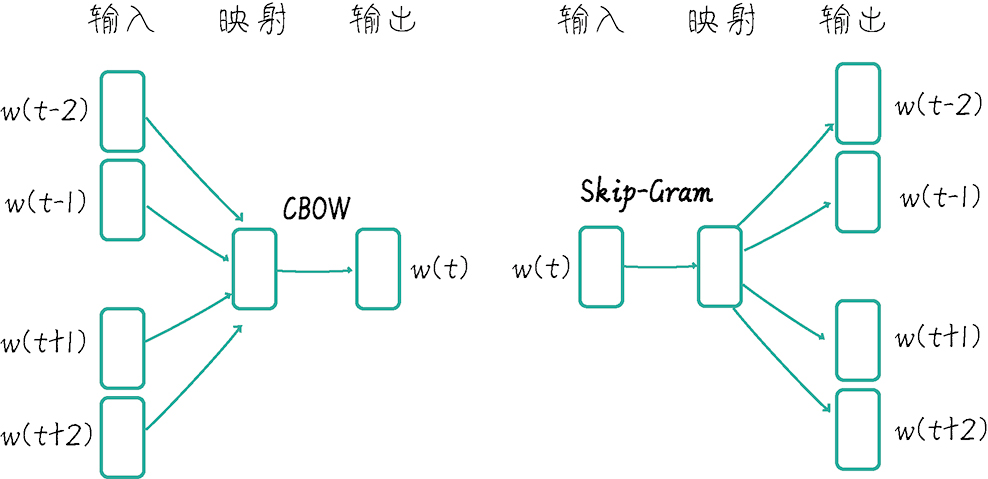
《GPT 图解》笔记:N-Gram、NPLM、LSTM
Ying’s Blog
·

一分钟读论文:《把百亿模型装进手机:TIDE实现扩散语言模型跨架构蒸馏》
Micropaper
·
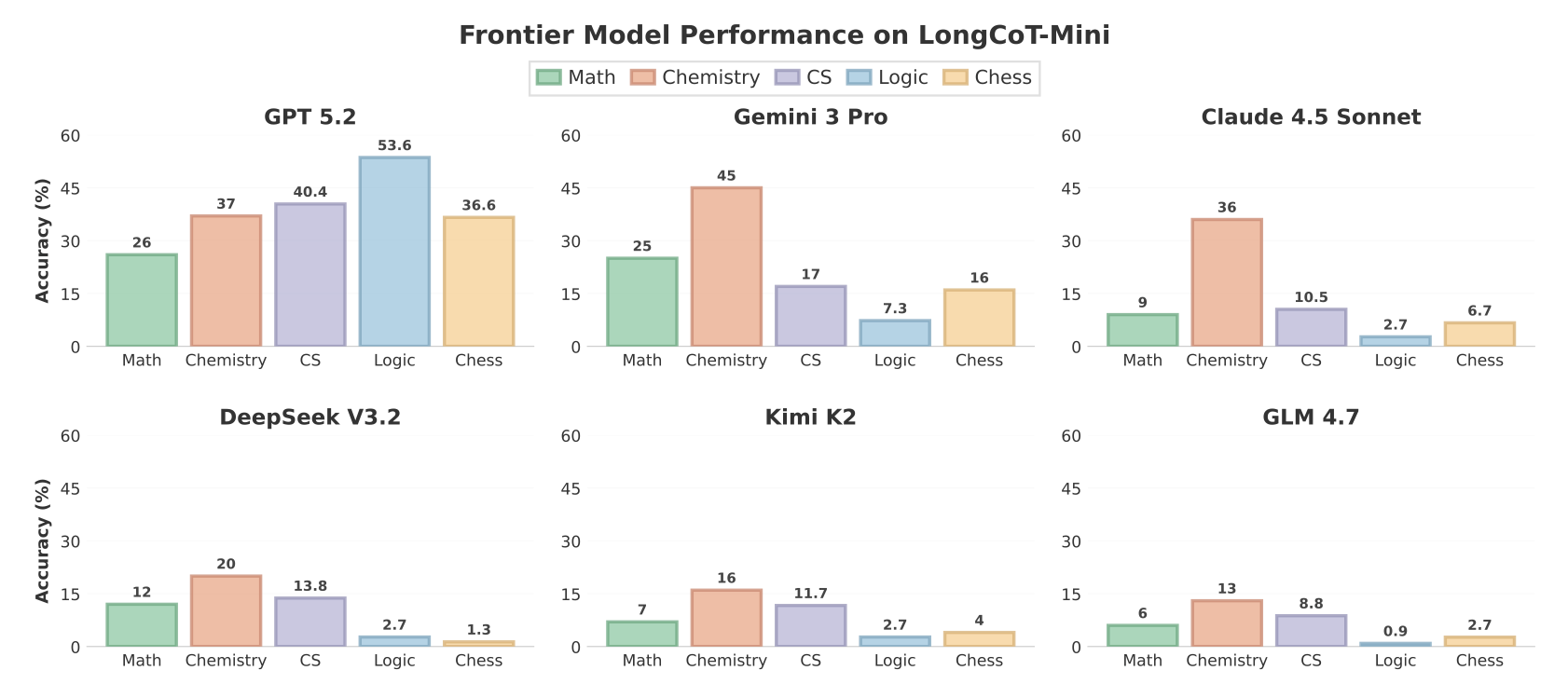
关于管理不善的天才假说的小型练习(长链推理中的语言模型)
blank
·

一分钟读论文:《用扩散语言模型统一多模态理解与生成》
Micropaper
·