

Harness 工程可视化:在 Vibe Coding 中重建工程可控性
phodal
·
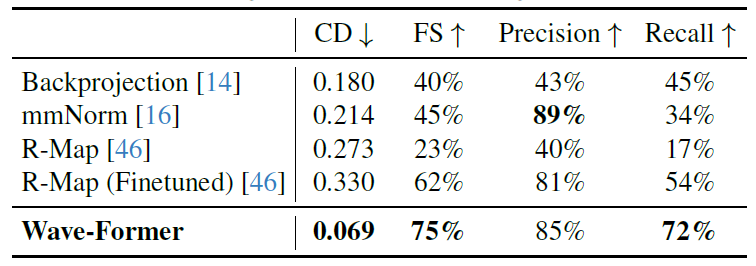
高精度重建完全遮挡物体,MIT团队利用生成式AI改进无线视觉系统,最高精度达85%
HyperAI超神经
·

Digg的公开测试版在仅仅两个月后关闭,原因是遭遇AI机器人垃圾信息
The Verge
·
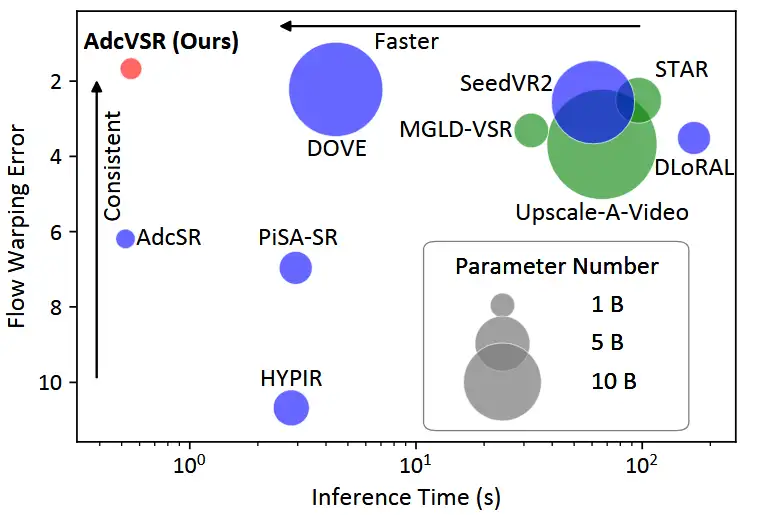
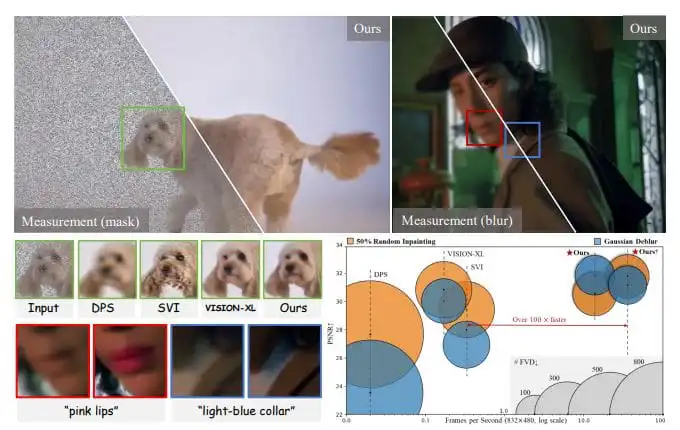

英伟达提出ReaSyn,借鉴思维链类比分子合成,实现超高重建率与路径多样性
HyperAI超神经
·



修复还是重建?拯救失败软件项目的真实成本
DEV Community
·

为什么Next.js在开发中如此缓慢?
DEV Community
·

三天重建:私信回归——比以往更好
DEV Community
·

我们失去了一切(好吧,几乎一切)
DEV Community
·

如何解决.NET项目中“进程无法访问文件,因为它被另一个进程使用”的错误
DEV Community
·


