本文对四款国产大模型(GLM 5.1、Kimi K2.6、Mimo v2.5 Pro 和 DeepSeek V4 Pro)的编码能力进行了实测。结果显示,这些模型在短链路和简单任务中表现良好,但在复杂工程中容易出现上下文丢失和逻辑错误。尽管能够生成代码,但在高风险模块上仍需人工审核以确保安全性和准确性。总体而言,国产模型可作为辅助工具,但不应完全依赖。
在端侧部署小参数模型时,qwen30b-a3b模型效果优于ollama模型。使用C#调用ollama模型时,参数定义存在问题,引用类型或嵌套会导致上下文丢失。建议使用Microsoft.Extensions.AI.OpenAI,ollama部分兼容OpenAI格式请求。
本文探讨了与GPT-4o协同编程的经历。尽管初期顺利,但在重构代码时,GPT-4o出现了上下文丢失和错误建议,导致无限递归等问题。尽管在某些方面表现良好,但协同编程需要信任和精确性,因此建议使用版本控制和调试工具。总体而言,GPT-4o的表现仍需进一步评估。
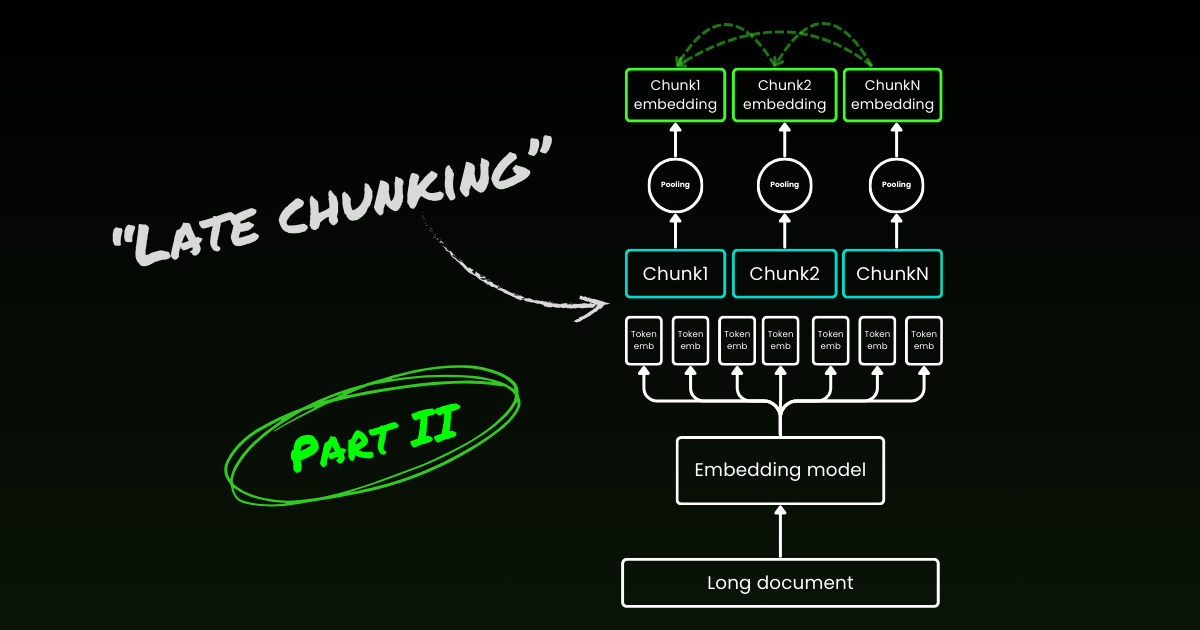
文章讨论了文档分块中的断点选择和上下文丢失问题。传统方法在分块后嵌入,导致上下文丢失。晚分块方法先编码整个文档,再根据断点进行均值池化,保留全局上下文。实验显示,晚分块对断点不敏感,性能优于传统方法,无需额外训练,适合长上下文嵌入,比使用LLM更高效。
完成下面两步后,将自动完成登录并继续当前操作。