
晚分块的真正含义与误解:第二部分
内容提要
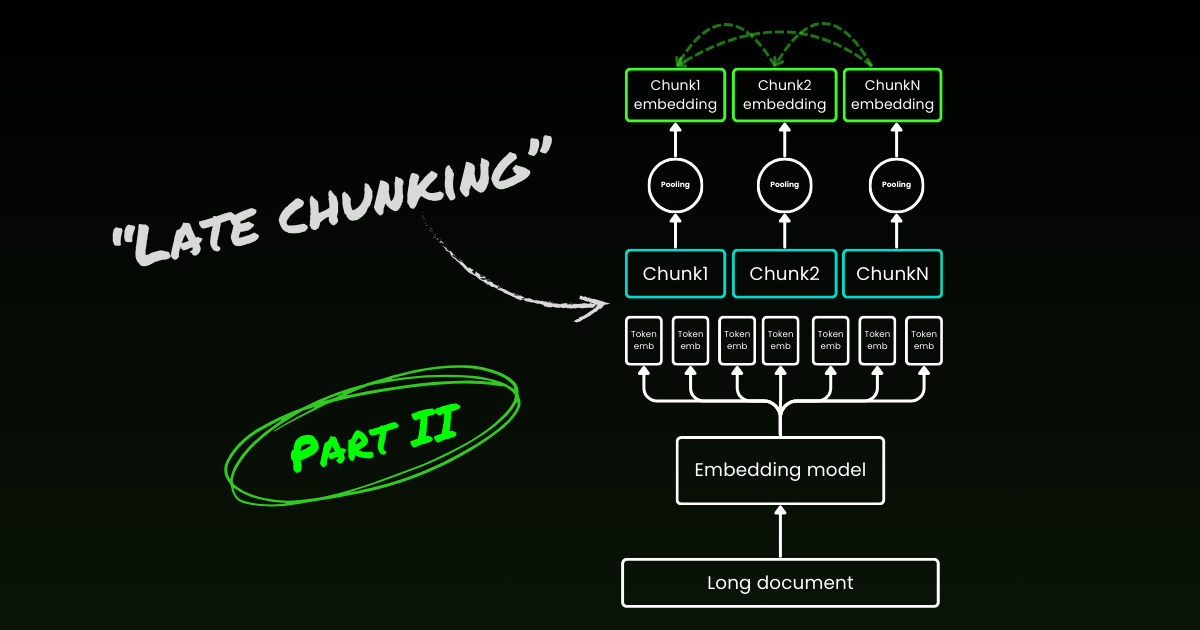
文章讨论了文档分块中的断点选择和上下文丢失问题。传统方法在分块后嵌入,导致上下文丢失。晚分块方法先编码整个文档,再根据断点进行均值池化,保留全局上下文。实验显示,晚分块对断点不敏感,性能优于传统方法,无需额外训练,适合长上下文嵌入,比使用LLM更高效。
关键要点
-
文章讨论了文档分块中的断点选择和上下文丢失问题。
-
传统方法在分块后嵌入,导致上下文丢失。
-
晚分块方法先编码整个文档,再根据断点进行均值池化,保留全局上下文。
-
实验显示,晚分块对断点不敏感,性能优于传统方法。
-
晚分块无需额外训练,适合长上下文嵌入,比使用LLM更高效。
-
分块的两个主要问题是断点选择和上下文信息丢失。
-
晚分块方法在处理上下文丢失时不依赖于理想的断点。
-
晚分块的实验结果显示,即使使用固定的分块边界,性能也优于简单的分块方法。
-
晚分块的条件依赖是双向的,能够保留全局上下文信息。
-
晚分块不需要额外的训练,适用于任何使用均值池化的长上下文嵌入模型。
-
与Anthropic的上下文检索方法相比,晚分块更具成本效益和效率。
-
晚分块是一种简单有效的方法,快速且对边界提示具有高度的弹性。
延伸解读
晚分块的优势
晚分块方法通过先编码整个文档,再进行均值池化,有效解决了上下文丢失的问题。这种方法不仅提高了长上下文嵌入的效率,还避免了对理想断点的依赖,使得在处理复杂文档时更加灵活。
与传统方法的比较
传统的分块方法在处理文档时容易导致上下文信息的丢失,而晚分块则通过全局上下文的保留,显著提升了性能。实验结果表明,即使使用固定的分块边界,晚分块的效果也优于简单的分块方法。
应用场景与限制
晚分块适用于任何使用均值池化的长上下文嵌入模型,且无需额外训练。然而,在特定任务如问答系统中,适当的微调仍然可以进一步提升性能,因此在实际应用中需根据具体需求进行调整。
延伸问答
晚分块方法如何解决上下文丢失问题?
晚分块方法通过先编码整个文档,然后根据断点进行均值池化,保留全局上下文,从而解决上下文丢失问题。
晚分块与传统分块方法相比有什么优势?
晚分块对断点不敏感,性能优于传统方法,无需额外训练,适合长上下文嵌入,且效率更高。
晚分块是否需要额外的训练?
晚分块不需要额外的训练,可以直接应用于任何使用均值池化的长上下文嵌入模型。
晚分块的条件依赖是怎样的?
晚分块的条件依赖是双向的,能够保留全局上下文信息,而不是仅依赖于前面的块。
晚分块在处理固定分块边界时的表现如何?
实验表明,晚分块即使在使用固定的分块边界时,性能也优于简单的分块方法。
晚分块与Anthropic的上下文检索方法有什么不同?
晚分块是一种低成本、高效率的方法,而Anthropic的方法依赖于将整个文档发送给LLM进行上下文丰富,成本较高。
