本研究提出DINT变换器,改进了DIFF变换器在全局上下文建模和数值稳定性方面的不足,通过差分-积分机制增强了对全局依赖的捕捉能力。实验结果表明,DINT在长上下文语言建模和关键信息检索中表现优异。
本研究提出了一种新方法,解决现有引用视频对象分割(RVOS)在短视频片段中缺乏全局上下文的问题。通过引入自然语言理解和时间建模,增强了Segment-Anything 2(SAM2)模型,使其在流式场景中有效工作,保持上下文信息,并在多个基准测试中取得优异成果。
JavaScript 代码运行时会创建执行上下文,包括全局执行上下文和函数执行上下文。全局上下文分为创建阶段(变量初始化为undefined)和执行阶段(逐行执行代码)。调用函数时,会为其创建新的上下文,局部变量同样初始化为undefined,执行后返回结果。
本研究探讨了语言模型在图像生成中的应用,揭示了图像标记与文本标记的随机性差异对训练的挑战。小模型在捕捉全局上下文方面有限,而大模型则显著提升,为视觉生成领域的设计提供了重要见解。
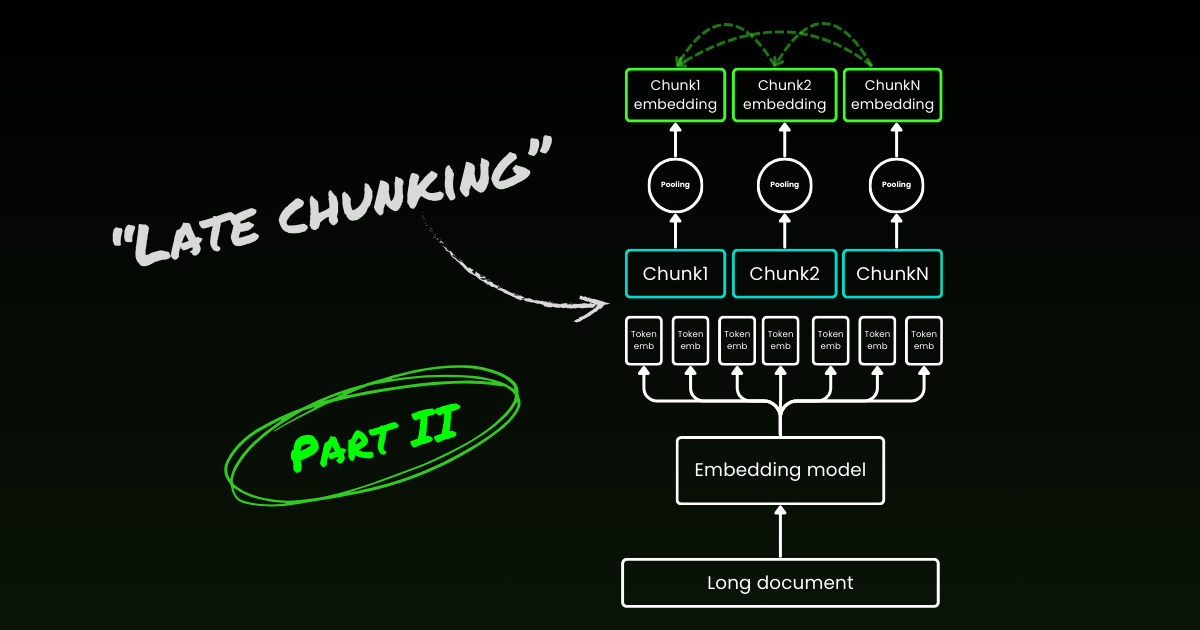
文章讨论了文档分块中的断点选择和上下文丢失问题。传统方法在分块后嵌入,导致上下文丢失。晚分块方法先编码整个文档,再根据断点进行均值池化,保留全局上下文。实验显示,晚分块对断点不敏感,性能优于传统方法,无需额外训练,适合长上下文嵌入,比使用LLM更高效。
LC-MAE是一种自我监督学习框架,利用全局上下文理解视觉表示,减少输入的空间冗余。在ImageNet-1K上使用ViT-B实现了84.2%的top-1准确率,比基准模型提高了0.6%。在下游任务中,LC-MAE取得了显著的性能提升,并在多个鲁棒性评估指标上表现优异。
该研究基于2D TransUNet体系结构,引入基于Transformer的编码器和解码器,实现全局上下文提取和候选区域精炼,适用于医学任务。实验证明,TransUNet在医学应用中表现出色,超越竞争对手。
本文介绍了Django中的上下文处理器,它是一个接收HttpRequest对象并返回包含上下文变量字典的Python函数。通过定义全局上下文,开发者可以在所有模板中访问这些变量,从而简化网站开发。文中还提供了创建和配置上下文处理器的示例代码。
完成下面两步后,将自动完成登录并继续当前操作。