


长期运行代理的上下文窗口管理:策略与权衡
MachineLearningMastery.com
·

上下文窗口不是记忆:AI代理开发者需要理解的内容
MachineLearningMastery.com
·

如何应对RAG系统中的小上下文窗口限制
freeCodeCamp.org
·

GLM 5.2现已在AI Gateway上线
Vercel News
·

Nvidia最新模型现已上线
The New Stack
·

AI Gateway上的Grok 4.3
Vercel News
·

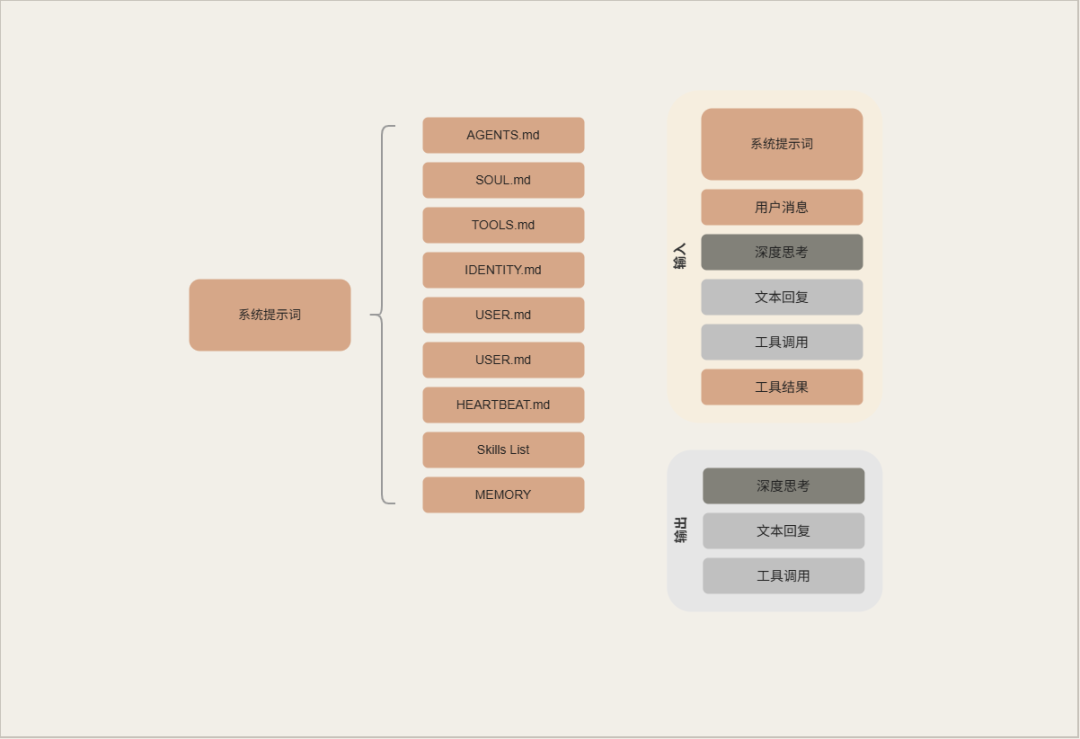
Modular:零日发布:Gemma 4在NVIDIA和AMD上的最快性能
Modular Blog
·
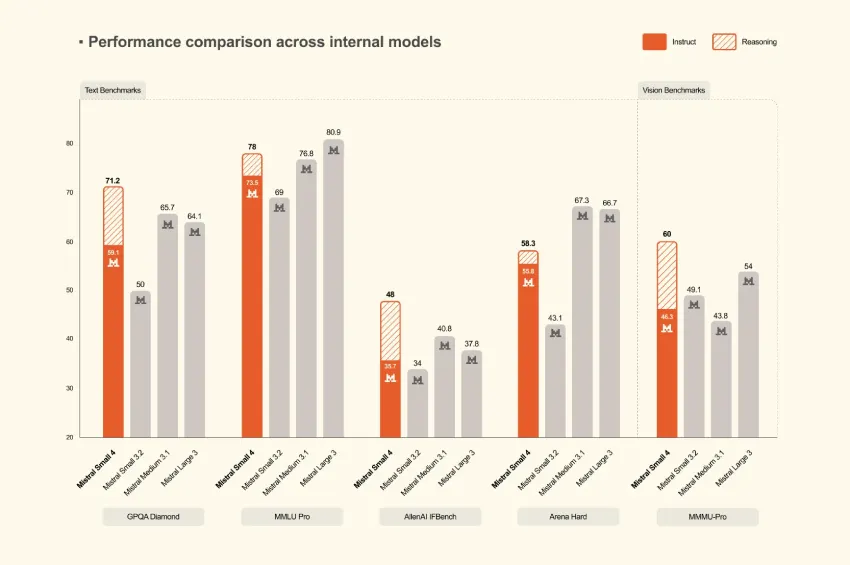
Anthropic对Claude的最长提示进行了重要的定价调整
The New Stack
·
.png)
