
Mistral AI 发布 Mistral Small 4:一款拥有 1190 亿参数的 MoE 模型
内容提要
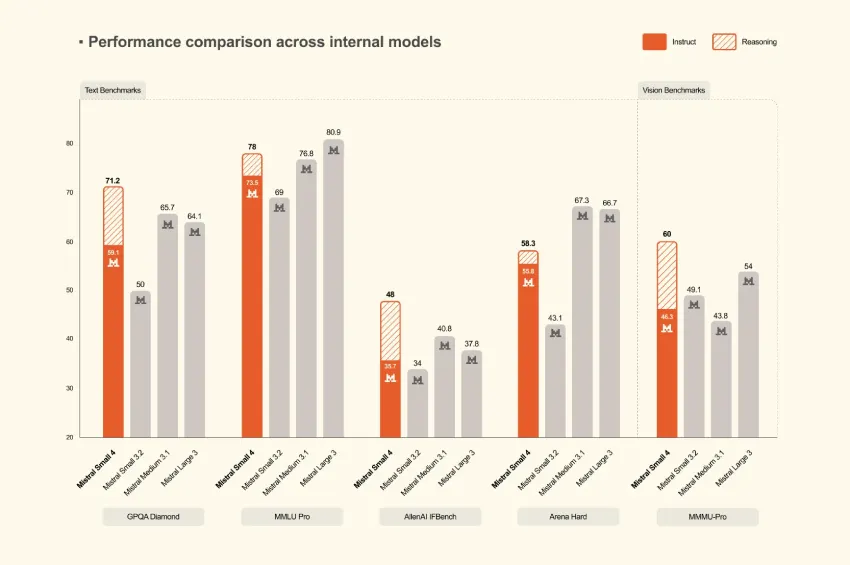
Mistral AI 发布了 Mistral Small 4,具备指令执行、推理和多模态理解功能,支持256k上下文窗口,具有可配置推理强度,提升了推理效率和经济性,适合通用聊天和复杂推理。
关键要点
-
Mistral AI 发布了 Mistral Small 4,整合了多种功能于一个模型中。
-
该模型为混合专家 (MoE) 模型,包含128位专家,每个token有4位活跃专家。
-
支持256k的上下文窗口,适用于长文档分析和多模态任务。
-
引入可配置的推理强度,允许开发者根据需求调整推理深度。
-
在延迟优化下,完成时间缩短40%,吞吐量提高3倍。
-
推理性能与GPT-OSS 120B持平或更优,且输出更短。
-
提供自托管架构指导,建议使用特定的NVIDIA硬件配置。
延伸解读
长上下文的实际应用
Mistral Small 4 支持256k的上下文窗口,这在长文档分析和多模态任务中具有重要意义。它减少了对数据分块和上下文剪枝的需求,使得处理复杂任务时更加高效,尤其适合需要处理大量信息的企业级应用。
可配置推理强度的优势
引入可配置的推理强度使得开发者能够根据需求动态调整推理深度。这种灵活性不仅提高了模型的适应性,还简化了部署流程,避免了在不同模型间切换的复杂性,适合多样化的应用场景。
性能与经济性的平衡
Mistral Small 4 在推理效率上表现出色,完成时间缩短40%,吞吐量提高3倍。这表明该模型不仅在性能上与竞争对手持平,且在经济性上也有显著提升,适合需要高效处理的生产环境。
延伸问答
Mistral Small 4 的主要功能是什么?
Mistral Small 4 结合了指令执行、推理、多模态理解和智能体编码等功能,作为一个通用助手和推理模型运行。
Mistral Small 4 的架构特点是什么?
Mistral Small 4 是一个混合专家 (MoE) 模型,包含128位专家,每个token有4位活跃专家,总参数量为1190亿。
Mistral Small 4 支持多大的上下文窗口?
该模型支持256k的上下文窗口,适用于长文档分析和多模态任务。
如何调整 Mistral Small 4 的推理强度?
开发者可以通过设置 reasoning_effort 参数来调整推理强度,从而在延迟和推理深度之间进行权衡。
Mistral Small 4 的推理性能如何?
在推理基准测试中,Mistral Small 4 的性能与GPT-OSS 120B持平或更优,且输出更短。
Mistral Small 4 的部署要求是什么?
建议的最低部署配置为4块NVIDIA HGX H100或2块NVIDIA HGX H200,或1块NVIDIA DGX B200。
