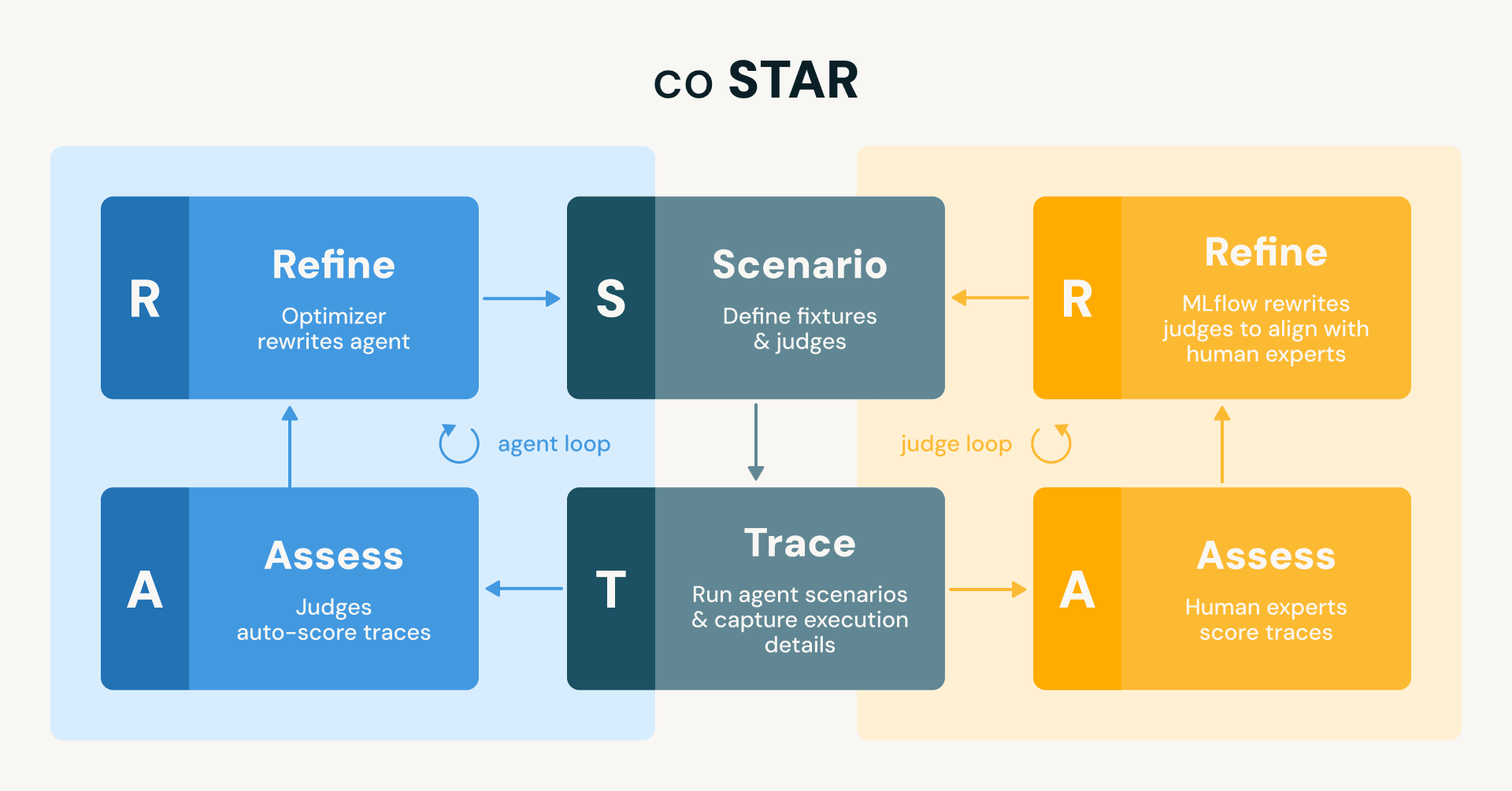
在Databricks,我们开发了coSTAR框架,通过自动化测试和专家评估优化代码助手,解决无测试编码问题,确保代码质量与可靠性。该框架利用场景定义、追踪捕获和评估机制,持续提升代理性能和开发效率。
在国际数学奥林匹克组织的支持下,IMO 2025项目由多个团队合作完成,Thang Luong和Edward Lockhart负责协调。项目依赖于Deep Think团队的研究,专家们提供了数据和评估,最终确认提交的答案完整且正确。
本研究探讨了审稿人信心评分与评审内容的一致性,提出了利用深度学习和自然语言处理技术的方法。研究发现,高信心评分与论文被拒绝存在相关性,验证了专家评估的公正性。
本研究针对国家技术图书馆开放存取目录的自动主题标签化问题,提出了一种基于多种大语言模型的组合方法。通过少量示例训练和后处理步骤,我们有效地将生成的关键词映射到目标词汇,并通过专家评估取得最佳结果。
完成下面两步后,将自动完成登录并继续当前操作。