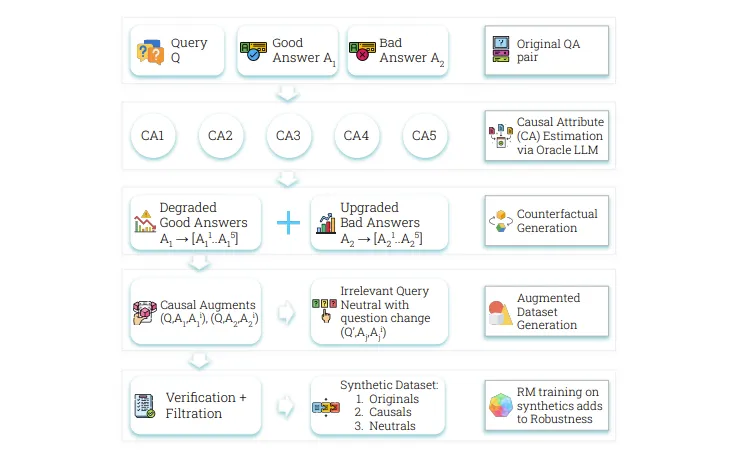
奖励模型(RM)面临奖励黑客攻击的挑战,难以区分表面属性与真实质量。Crome框架通过因果增强和中性增强策略,提高了RM的稳健性和准确性,有效解决了训练中的虚假相关性问题,优于传统方法。
完成下面两步后,将自动完成登录并继续当前操作。