
Crome:Google DeepMind 的因果框架,用于 LLM 对齐中建立稳健奖励模型
内容提要
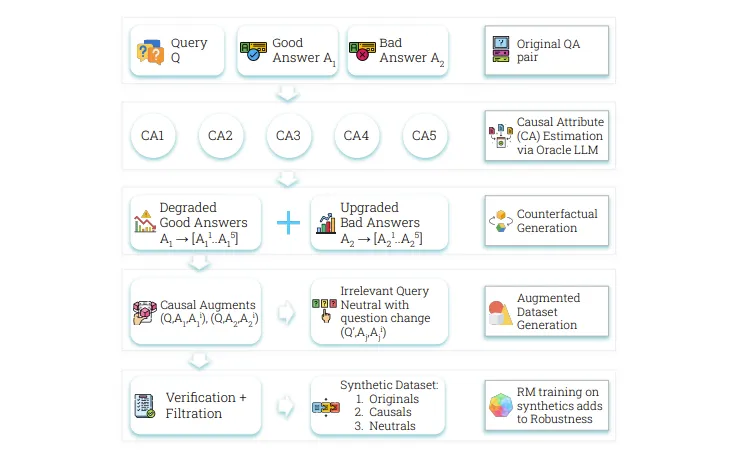
奖励模型(RM)面临奖励黑客攻击的挑战,难以区分表面属性与真实质量。Crome框架通过因果增强和中性增强策略,提高了RM的稳健性和准确性,有效解决了训练中的虚假相关性问题,优于传统方法。
关键要点
-
奖励模型面临奖励黑客攻击的挑战,难以区分表面属性与真实质量。
-
Crome框架通过因果增强和中性增强策略,提高了RM的稳健性和准确性。
-
现有RM方法未能有效解决虚假相关性问题,导致模型脆弱。
-
Crome通过添加偏好数据集和定向反事实示例,训练RM区分真正的质量驱动因素。
-
Crome的因果增强和中性增强策略显著提高了RewardBench的准确率。
-
Crome的运作分为生成反事实数据和使用特定损失函数进行训练两个阶段。
-
在多种基础模型上,Crome在安全性和推理类别中表现优异。
-
Crome为基础模型训练的合成数据生成开辟了新的研究方向,可能对未来的语言模型对齐发展有益。
延伸解读
奖励模型的脆弱性
奖励模型在训练过程中容易受到奖励黑客攻击,导致其无法有效区分表面属性与真实质量。这种脆弱性可能影响模型的实际应用效果,尤其是在需要高准确度和可靠性的场景中。理解这一点有助于研究人员在设计模型时更加关注因果关系的建立。
Crome框架的创新之处
Crome框架通过因果增强和中性增强策略,显著提高了奖励模型的稳健性和准确性。这种方法不仅解决了虚假相关性的问题,还为未来的语言模型对齐提供了新的研究方向。研究人员应关注如何将这些策略应用于其他领域,以提升模型的整体性能。
未来研究的潜力
Crome的成功为合成数据生成开辟了新的研究方向,尤其是在因果属性验证方面。未来的研究可以探索如何进一步优化这些策略,以应对更复杂的奖励黑客攻击和虚假相关性问题,从而推动语言模型的稳健性和安全性提升。
延伸问答
Crome框架的主要功能是什么?
Crome框架通过因果增强和中性增强策略,提高奖励模型的稳健性和准确性,解决训练中的虚假相关性问题。
奖励模型面临哪些主要挑战?
奖励模型面临奖励黑客攻击的挑战,难以区分表面属性与真实质量,导致模型脆弱。
Crome如何提高奖励模型的准确性?
Crome通过添加偏好数据集和定向反事实示例,训练奖励模型区分真正的质量驱动因素和表面线索。
Crome的运作流程分为哪两个阶段?
Crome的运作分为生成反事实数据和使用特定损失函数进行训练两个阶段。
Crome在安全性和推理能力方面的表现如何?
Crome在安全性和推理类别中表现优异,特别是在RewardBench上排名准确率显著提升。
Crome对未来语言模型对齐的发展有什么影响?
Crome为基础模型训练的合成数据生成开辟了新的研究方向,可能对未来的语言模型对齐发展有益。
