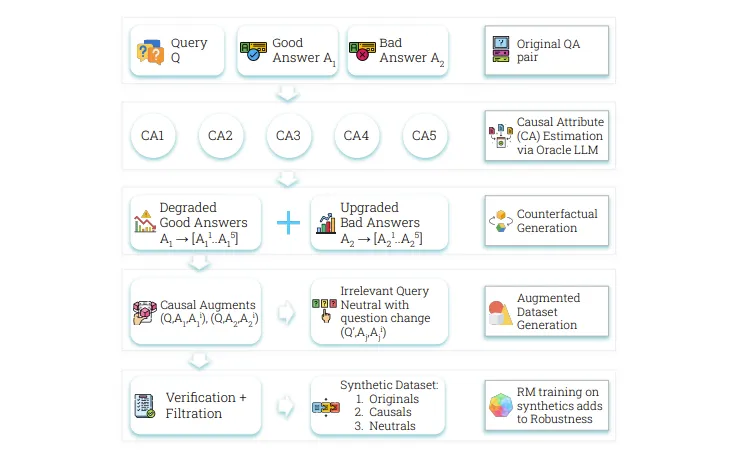
奖励模型(RM)面临奖励黑客攻击的挑战,难以区分表面属性与真实质量。Crome框架通过因果增强和中性增强策略,提高了RM的稳健性和准确性,有效解决了训练中的虚假相关性问题,优于传统方法。
本研究提出MiMu方法,旨在解决模型依赖特征与标签之间的虚假相关性,减轻捷径学习现象,从而提高模型的稳健性和泛化能力。实验结果表明,该方法在自然语言处理和计算机视觉任务中显著增强了模型的鲁棒性。
本研究提出了一种新颖的数据修剪技术,有效解决深度神经网络中的虚假相关性问题,实验结果表明该技术在识别虚假信息方面表现优异。
本研究提出了一种结合因果学习与神经混沌学习的新方法,旨在解决深度学习在捕捉因果结构和高能耗方面的问题,有效减少虚假相关性,提升分类与预测效果。
本研究提出了一种新方法,通过RegText框架在自然语言数据集中注入虚假相关性,以遵循数据保护法律,限制新模型对公共数据的学习。
本研究提出RaVL方法,旨在发现和缓解微调视觉语言模型中的虚假相关性。通过区域级聚类识别导致分类错误的图像特征,并利用区域感知损失函数优化微调过程,从而显著提升模型性能。实验证明,RaVL在解决虚假相关性方面效果显著,具有广泛应用潜力。
本文探讨机器学习中的鲁棒性表征及虚假相关性,提出基于最小充分统计量的鲁棒表征方法,并利用分组分布式优化应对数据偏移。研究表明,该方法在图像和语言任务中表现优越。此外,提出了多任务学习的偏见缓解技术,以优化准确性与公平性之间的权衡,增强模型的可解释性。实验验证了方法的有效性,解决了偏见缓解的可推广性问题。
本研究提出了一种创新的解偏因果推断网络(DCIN),通过结构因果模型分解干扰因素,消除虚假相关性,减轻外部知识的偏见。实验结果显示,DCIN在Flickr30K和MSCOCO数据集上表现出优越性能。
本文探讨了机器学习中的虚假相关性问题,提出了识别和减轻这些影响的方法,包括可解释框架DISC和概念平衡技术。研究指出,时序依赖性和标签不平衡会导致模型性能下降,强调增强模型可解释性的重要性以应对伪相关性,并综述了现有方法及未来研究挑战。
本文研究了神经网络分类器的一致性及其与准确性的关系,提出了一种利用无标签数据进行OOD预测的算法。研究发现虚假相关性会降低模型在野外数据上的表现,并提出通过引入“不变”特征来改善数据转移的方法。此外,探讨了深度神经网络在处理未知分布数据时的过度自信问题,并提出了改进的OOD检测框架。
本文探讨了机器学习中的虚假相关性问题,并提出了多种提高模型鲁棒性的方法,包括因果效应估计、特征选择和自监督去偏置框架。实验结果表明,这些方法在情感分类和毒性检测等任务中显著提升了分类准确性,尤其在虚假相关性较高的情况下表现优越。
本文探讨机器学习中的鲁棒性表征及虚假相关性,提出基于最小充分统计量的鲁棒表征概念,并通过分组分布式鲁棒优化方法解决输入分布偏移问题。研究表明,该方法在图像和语言任务中表现出显著优势。
本文探讨了因果推断和去偏方法在改善机器学习模型性能中的应用,特别是针对虚假相关性和数据偏差。提出了R2R和XCR等框架,旨在提升模型的公平性和准确性,并通过实证研究验证了其有效性。
完成下面两步后,将自动完成登录并继续当前操作。