后训练是一个复杂的数据流水线,包含多个阶段,如SFT、奖励模型和策略优化。每个阶段旨在将预训练模型转变为更符合人类指令和偏好的模型。SFT主要调整回答格式,奖励模型提供训练信号,策略优化提升生成候选的能力。评测确保模型的安全性和准确性,整体流程强调数据回流和持续优化,以提升模型性能和可靠性。
本文探讨了大模型对齐的流程,包括监督微调(SFT)、奖励模型(RM)和强化学习(RL)。对齐不仅提升了模型对指令的理解能力,还影响推理能力和回答质量。文章介绍了直接偏好优化(DPO)作为一种新方法,简化了训练流程,减少了模型数量,提高了效率。未来研究将关注可验证奖励和长上下文推理,以增强模型的推理能力和应用范围。
上海AI Lab提出的POLAR新范式通过参考答案灵活打分,提升了强化学习中奖励模型的可扩展性和泛化能力,克服了传统模型的局限性,展现出显著的Scaling效应。
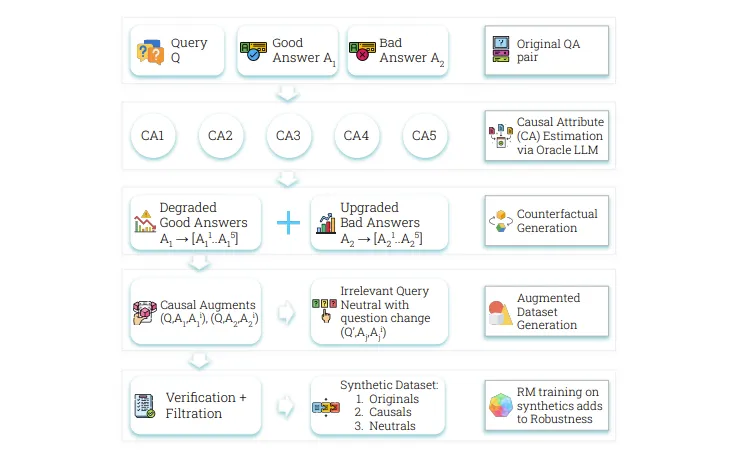
奖励模型(RM)面临奖励黑客攻击的挑战,难以区分表面属性与真实质量。Crome框架通过因果增强和中性增强策略,提高了RM的稳健性和准确性,有效解决了训练中的虚假相关性问题,优于传统方法。
张丽及其团队在微软亚洲研究院引入“System2”概念,提升大模型的深度推理能力。通过蒙特卡洛搜索算法,7B模型的数学推理能力接近OpenAI的o1,激发了学术界的广泛讨论。她指出智商和推理能力是大模型应用的关键,未来将继续优化奖励模型并扩展任务领域。
本研究提出了一种新颖的数据标注方法,解决了现有过程奖励模型在长链推理中仅关注初始错误的问题。通过引入错误传播和终止概念,显著提升了模型在自我纠正和推理方面的性能,实验结果优于现有模型。
本研究提出R3框架,以解决现有奖励模型在可控性和可解释性方面的不足,从而增强语言模型与人类价值观的一致性和灵活性。
清华、复旦和港科大联合发布RM-BENCH基准,旨在评估奖励模型的认知敏锐度,解决“形式大于内容”的问题。该基准关注模型对细微内容差异的敏感性和风格偏差的鲁棒性,涵盖聊天、代码、数学和安全等领域。研究表明,现有奖励模型在这些领域表现不佳,亟需改进。
本文探讨了基于人类反馈的强化学习中奖励模型过度优化的问题,提出了一种新正则化方法——批量归零正则化(BSR),显著提升了模型的鲁棒性和泛化能力。
本研究提出了一种遍历生成流(EGF),旨在解决生成流网络在模仿学习中的训练难题,并优化了流匹配损失和奖励模型。实验结果表明其在2D任务和NASA数据集上有效。
本研究提出了一种通过奖励模型对视觉语言模型(VLM)进行过程监督的方法,显著提升了其在复杂图形用户界面交互中的表现,静态环境下一步行动准确率提高3.4%,动态环境任务成功率提高约33%。
本研究探讨了结合强化学习与符号执行技术以提升代码生成大语言模型(LLMs)微调性能的方法。改进后的奖励模型在生成代码质量上显著优于现有基准CodeRL,展示了符号执行的潜力。
该研究提出了一种新的可靠性度量指标“RETA”,旨在解决大型语言模型中奖励模型的不确定性问题,并提供了集成基准测试管道,帮助研究人员评估奖励模型的可靠性。实验结果表明,RETA在评估奖励模型的可靠性方面表现优异。
本研究提出了一种名为CHARM的校准方法,旨在解决奖励模型中的偏差问题,从而提高评估的准确性和与人类偏好的相关性,促进更公平可靠的奖励模型构建。
本文探讨了评估和提升AI生成文本的写作质量,提出了写作质量基准(WQ)和训练写作质量奖励模型(WQRM)。研究表明,WQRM在质量评估中表现优越,能够选择更高质量的输出。人类评估显示,使用WQRM选择的文本获得了66%的专家偏好,从而提升了AI写作系统的质量对齐。
研究团队提出了RLVR框架,将强化学习应用于医学、法律等多个领域,使用7B奖励模型显著提升了复杂任务的表现。通过软奖励机制,模型在处理非结构化答案时更加灵活,无需特定领域的标注。
普林斯顿大学的研究表明,训练狗和设计RLHF奖励模型都需要考虑奖励的多样性。奖励模型的准确性并不等同于优化效率,低奖励方差会减缓优化速度。因此,不同策略应采用不同的奖励模型,以提升优化效果。
本研究探讨了奖励模型在强化学习中的有效性,指出仅依赖准确性无法全面评估其教学能力。建议通过降低奖励方差来提高模型训练效率。
本文介绍了MPBench,一个多任务多模态基准,旨在评估过程级奖励模型(PRMs)在不同场景中的有效性,以提高推理准确性并推动多模态PRMs的发展。
本研究提出了EpicPRM框架,解决了现有过程监督训练数据构建方法的成本和质量问题。通过量化推理步骤的贡献和自适应二分搜索算法,提高了标注的精准度和效率。基于该框架构建的Epic50k训练数据集显著提升了奖励模型的推理能力。
完成下面两步后,将自动完成登录并继续当前操作。