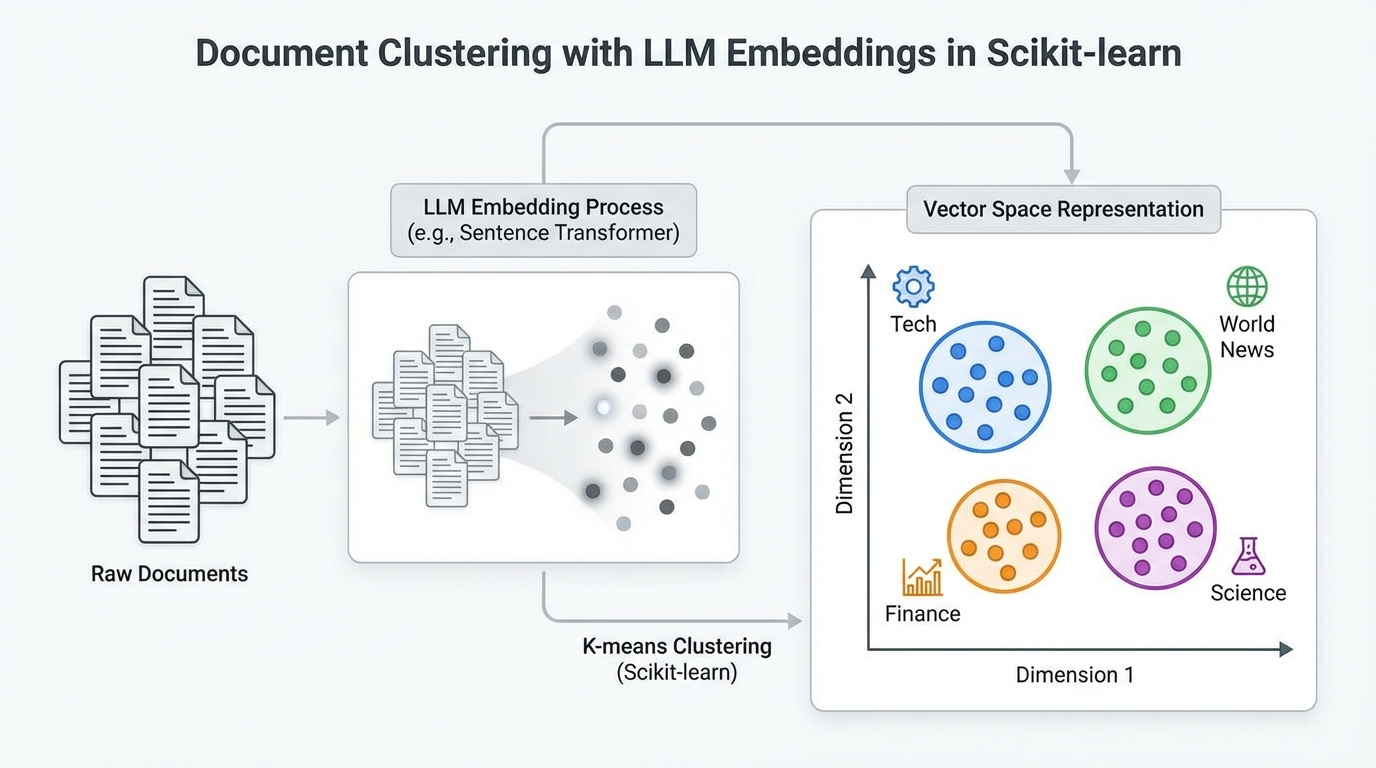
本文介绍了如何使用大语言模型嵌入和scikit-learn中的聚类算法对文本文件进行聚类,包括生成嵌入、应用k-means和DBSCAN算法,并评估效果。通过分析BBC新闻数据集,展示了识别文档共同主题的方法。
本文探讨了文本分段的挑战,提出了三种小型语言模型(simple-qwen-0.5、topic-qwen-0.5、summary-qwen-0.5),旨在优化长文档的分段并保持语义一致性。研究表明,topic-qwen-0.5在多主题文档中表现最佳,强调了分段在RAG系统中的重要性。
完成下面两步后,将自动完成登录并继续当前操作。