
使用大语言模型嵌入在Scikit-learn中进行文档聚类
内容提要
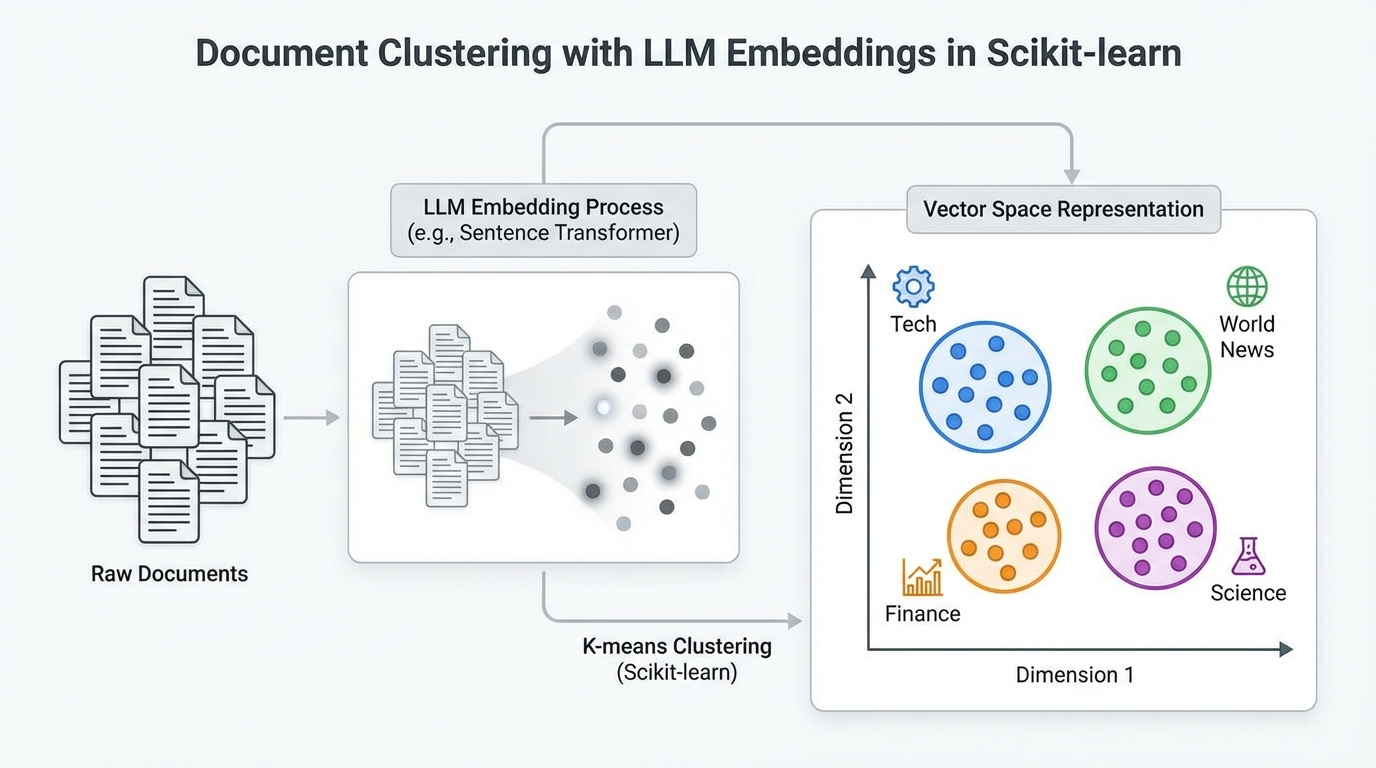
本文介绍了如何使用大语言模型嵌入和scikit-learn中的聚类算法对文本文件进行聚类,包括生成嵌入、应用k-means和DBSCAN算法,并评估效果。通过分析BBC新闻数据集,展示了识别文档共同主题的方法。
关键要点
-
使用大语言模型生成的嵌入可以更好地进行文档聚类,因为它们捕捉了上下文语义和整体文档意义。
-
通过使用预训练的句子变换器模型,可以将原始文本转换为数值向量,进而生成文档的嵌入。
-
应用k-means聚类算法时,需要预先指定聚类数量,并可以使用调整兰德指数(ARI)等指标评估聚类效果。
-
DBSCAN是一种基于密度的聚类算法,可以自动推断聚类数量,但对超参数敏感,需要仔细调整。
-
在BBC新闻数据集上,k-means聚类通常表现优于DBSCAN,因为文档之间的主题结构清晰,聚类相对分离。
延伸解读
大语言模型的优势
使用大语言模型生成的嵌入在文档聚类中具有明显优势。这些嵌入能够捕捉上下文语义,避免了传统方法如TF-IDF和Word2Vec的局限性,后者往往忽视了文本的整体意义。通过使用预训练的句子变换器模型,文档的语义表示更加准确,有助于提高聚类效果。
聚类算法的选择
在选择聚类算法时,k-means和DBSCAN各有优缺点。k-means需要预先指定聚类数量,适合于主题结构清晰的文档,而DBSCAN则能自动推断聚类数量,但对超参数敏感。对于BBC新闻数据集,k-means通常表现更佳,因为文档之间的主题相对分离。
评估聚类效果
评估聚类效果时,调整兰德指数(ARI)和轮廓系数是常用指标。ARI值接近1表示聚类结果与真实类别标签高度一致。通过这些指标,可以有效比较不同聚类算法的表现,帮助选择最合适的方法进行文档聚类。
延伸问答
如何使用大语言模型进行文档聚类?
可以通过生成文档的嵌入向量,然后应用聚类算法如k-means或DBSCAN来实现文档聚类。
k-means和DBSCAN在文档聚类中的表现如何?
在BBC新闻数据集上,k-means通常表现优于DBSCAN,因为文档之间的主题结构更清晰,聚类相对分离。
如何生成文档的嵌入向量?
可以使用预训练的句子变换器模型,将原始文本转换为数值向量,从而生成文档的嵌入。
DBSCAN算法的超参数如何影响聚类结果?
DBSCAN对超参数如邻域半径(eps)和最小样本数(min_samples)非常敏感,需仔细调整以获得良好结果。
如何评估聚类效果?
可以使用调整兰德指数(ARI)和轮廓系数等指标来评估聚类效果,值越接近1表示聚类效果越好。
为什么大语言模型的嵌入适合文档聚类?
大语言模型的嵌入能够捕捉上下文语义和整体文档意义,优于传统方法如TF-IDF和Word2Vec。
