

Scikit-Ollama用于Scikit-LLM/Ollama集成
MachineLearningMastery.com
·

使用Scikit-LLM构建端到端情感分析管道
MachineLearningMastery.com
·

使用Scikit-LLM进行多标签文本分类
MachineLearningMastery.com
·

使用Scikit-LLM与开源语言模型
MachineLearningMastery.com
·

Scikit-LLM与传统文本分类器的比较:何时应使用LLM?
MachineLearningMastery.com
·

如何使用Scikit-Learn、AWS Lambda和API Gateway部署无服务器垃圾邮件分类器
freeCodeCamp.org
·
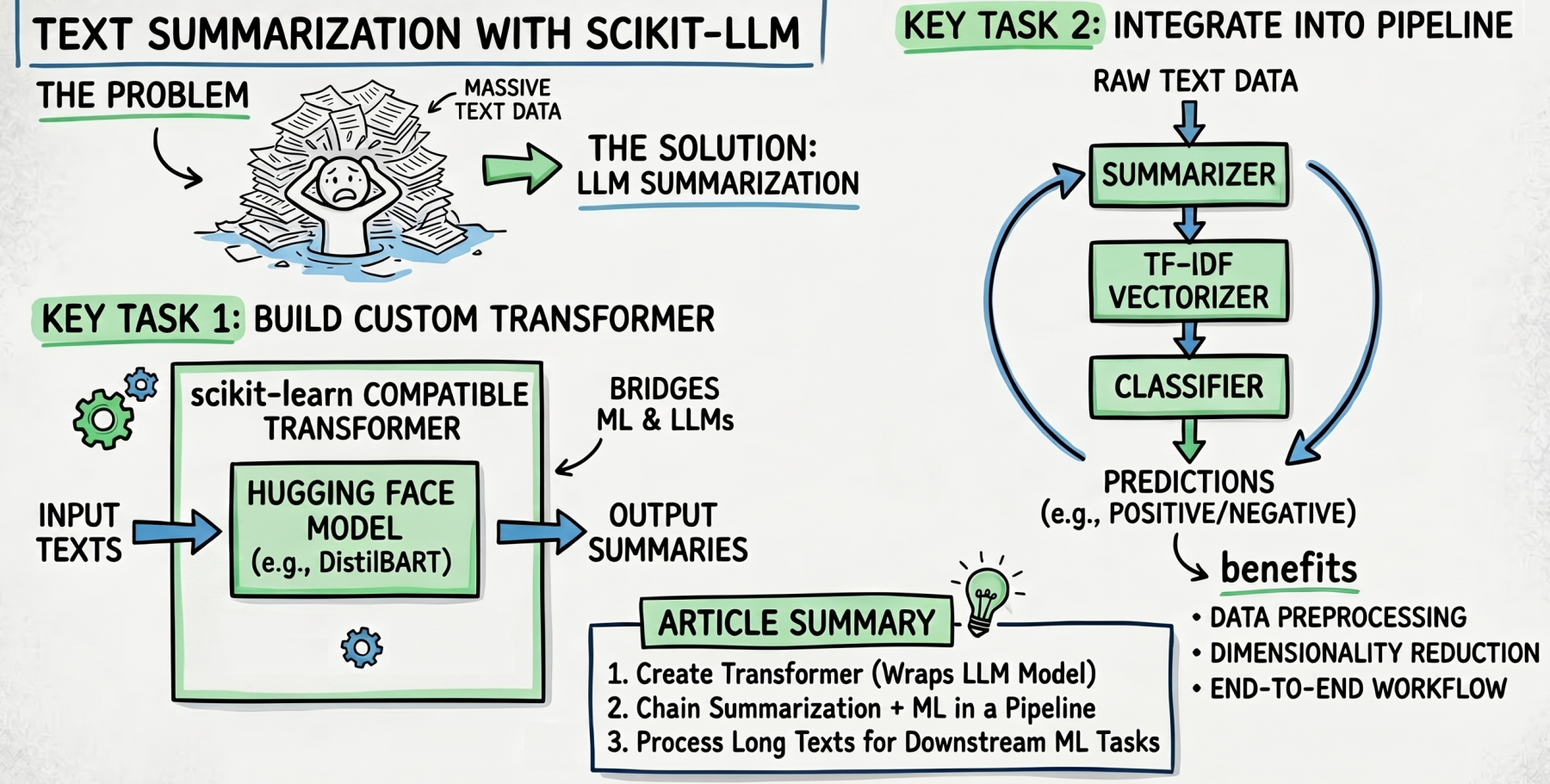
使用Scikit-LLM进行文本摘要
MachineLearningMastery.com
·

使用FastAPI训练、服务和部署Scikit-learn模型
MachineLearningMastery.com
·
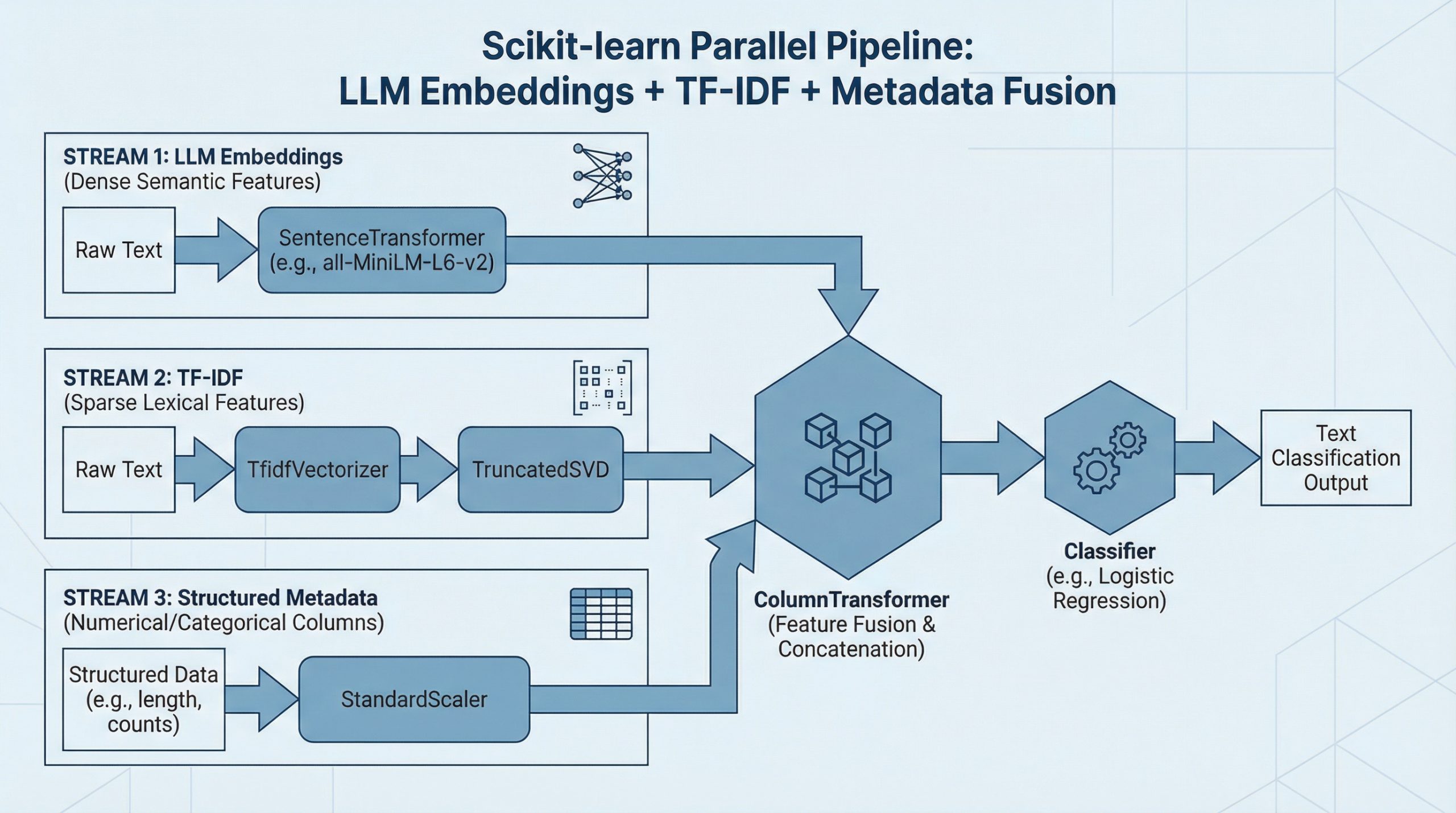
如何在一个Scikit-learn管道中结合LLM嵌入、TF-IDF和元数据
MachineLearningMastery.com
·
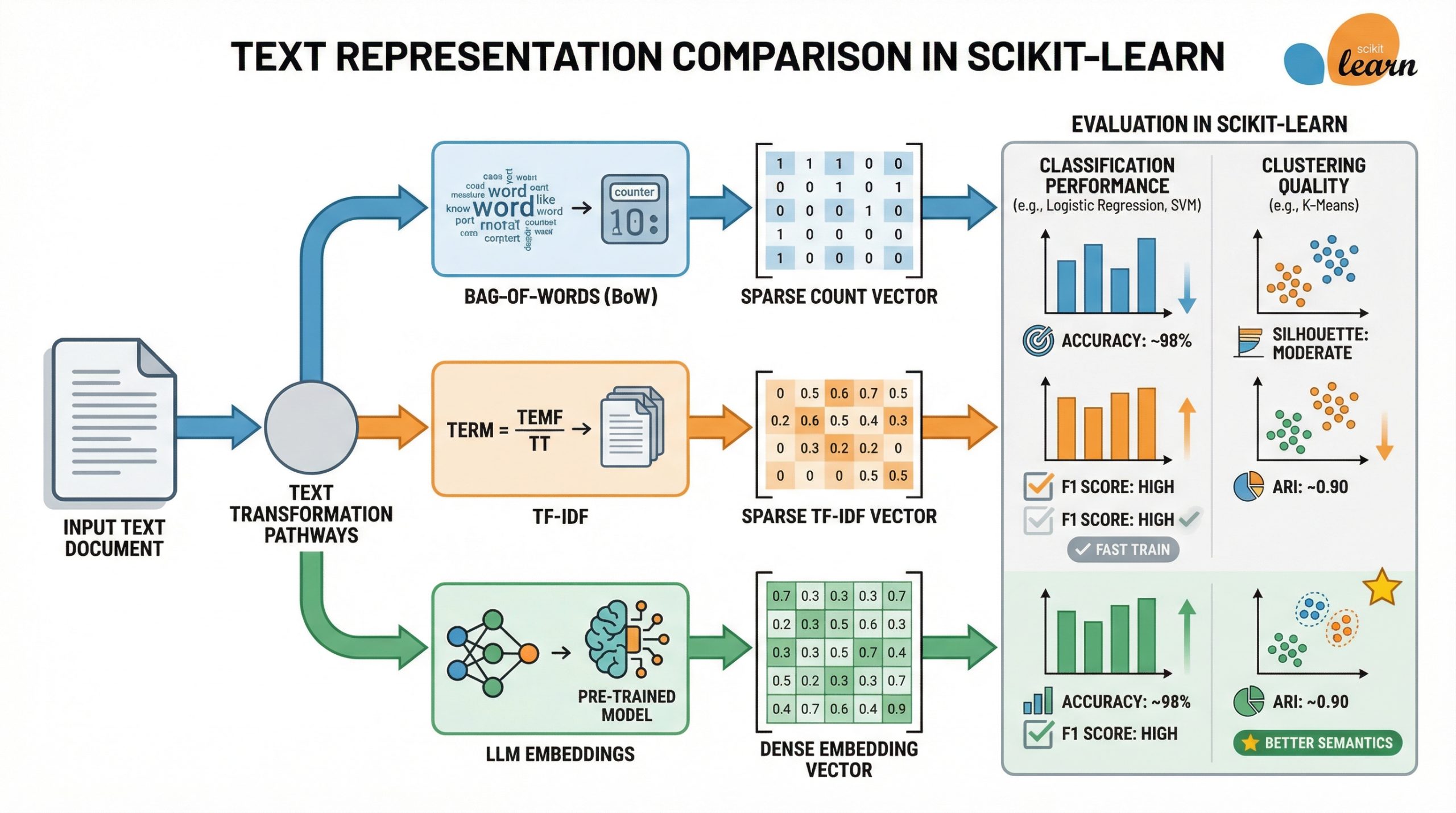
LLM嵌入与TF-IDF与词袋模型:在Scikit-learn中哪种效果更好?
MachineLearningMastery.com
·
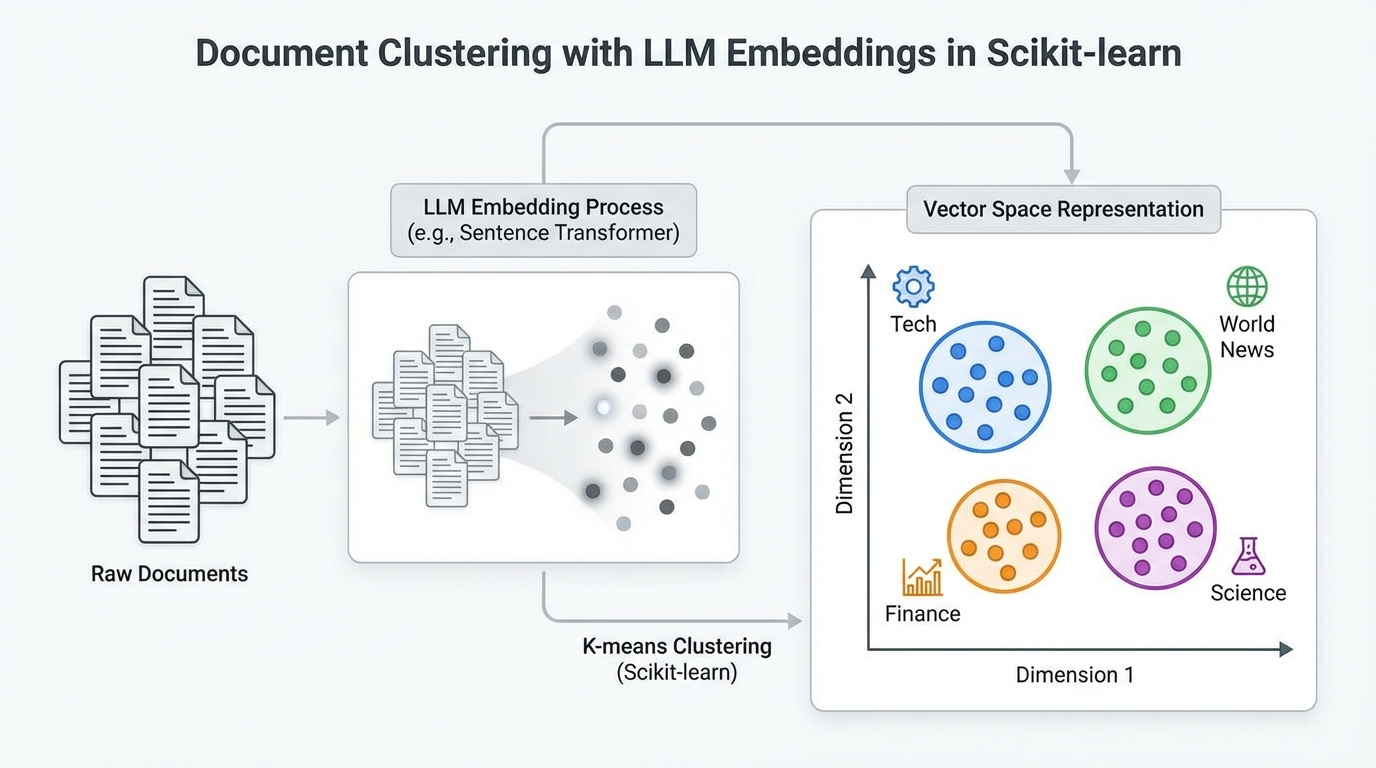
使用大语言模型嵌入在Scikit-learn中进行文档聚类
MachineLearningMastery.com
·
提升超参数调优的7个Scikit-learn技巧
KDnuggets
·

使用Dask和Scikit-learn处理大数据集
KDnuggets
·

从数据集到数据框再到部署:使用Pandas和Scikit-learn的第一个项目
KDnuggets
·

优化Scikit-learn交叉验证的七个技巧
MachineLearningMastery.com
·

提升工作流程效率的五个Scikit-learn管道技巧
MachineLearningMastery.com
·

使用Scikit-LLM进行零样本和少样本分类
MachineLearningMastery.com
·

利用LLM嵌入进行特征工程:增强Scikit-learn模型
MachineLearningMastery.com
·

超越GridSearchCV:Scikit-learn模型的高级超参数调优策略
MachineLearningMastery.com
·
如何结合Scikit-learn、CatBoost和SHAP构建可解释的树模型
MachineLearningMastery.com
·
