
LLM嵌入与TF-IDF与词袋模型:在Scikit-learn中哪种效果更好?
内容提要
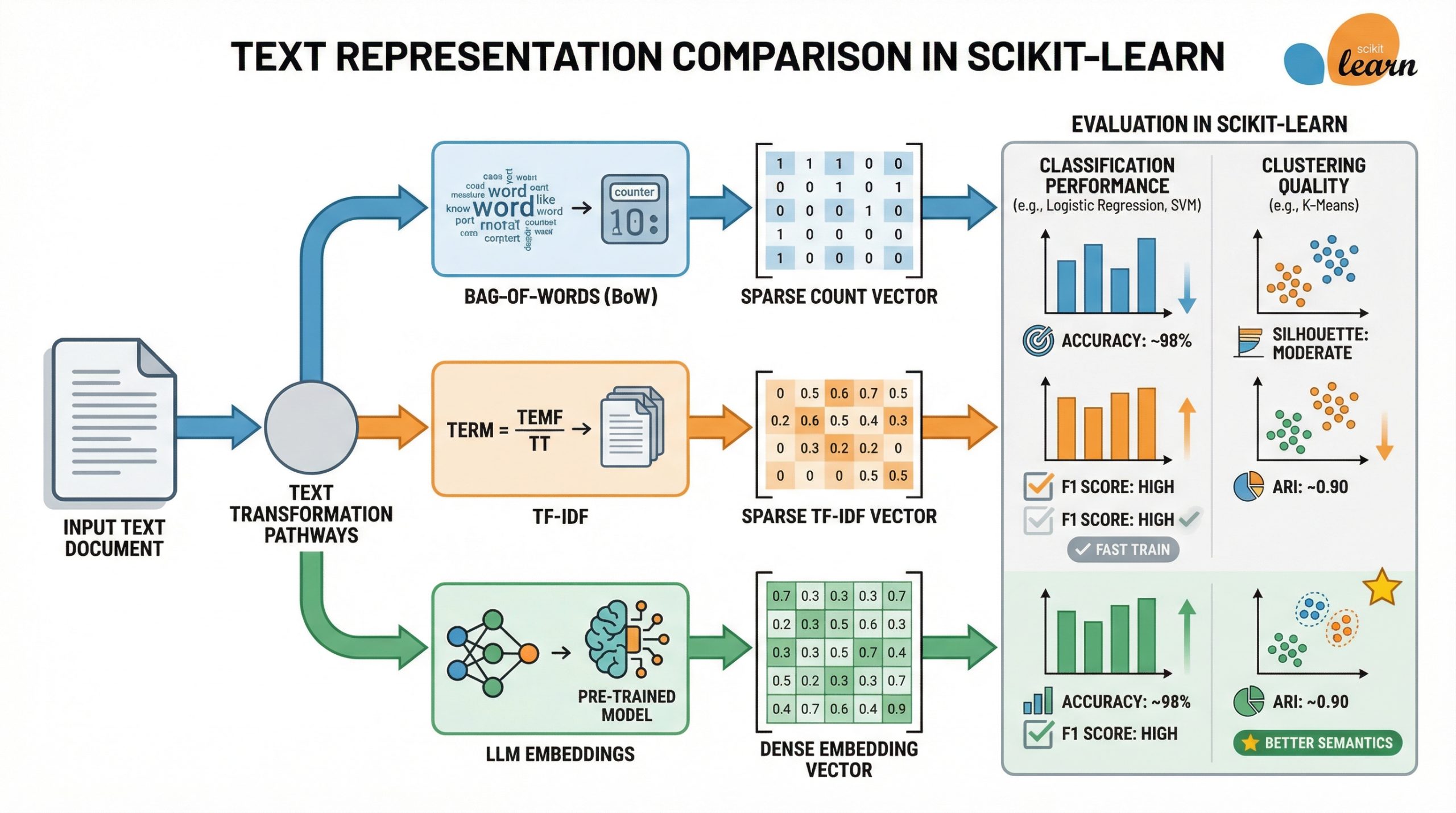
本文比较了词袋模型(BoW)、TF-IDF和LLM嵌入在Scikit-learn中的效果,使用BBC新闻数据集分析它们在文本分类和聚类中的表现。结果显示,TF-IDF与支持向量机组合在分类准确率上最佳,而LLM嵌入在聚类任务中表现更佳。建议在处理简单数据集时优先考虑传统方法。
关键要点
-
本文比较了词袋模型(BoW)、TF-IDF和LLM嵌入在Scikit-learn中的效果。
-
使用BBC新闻数据集分析这三种文本表示方法在文本分类和聚类中的表现。
-
TF-IDF与支持向量机组合在分类准确率上最佳,达到0.987。
-
LLM嵌入在聚类任务中表现更佳,调整兰德指数(ARI)为0.899。
-
建议在处理简单数据集时优先考虑传统方法,如TF-IDF和BoW。
-
LLM嵌入在简单且线性可分的数据集上未必优于传统方法,可能导致过拟合。
-
在聚类任务中,LLM嵌入能够更好地捕捉语义模式,适合无监督学习。
延伸解读
传统方法的优势
在处理简单且线性可分的数据集时,传统的文本表示方法如TF-IDF和词袋模型(BoW)表现优异。这些方法能够有效捕捉文本中的关键词和特征,适合于分类任务,尤其是在数据集清晰且类别分明的情况下。
LLM嵌入的适用场景
尽管LLM嵌入在聚类任务中表现出色,但在简单数据集上可能导致过拟合。对于复杂的、含有噪声或多样化文本的真实世界数据集,LLM嵌入能够更好地捕捉语义模式,适合无监督学习。
模型选择的考虑
选择合适的文本表示方法时,应考虑任务的复杂性和数据集的特性。对于简单任务,优先使用传统方法可以节省计算资源和时间,而对于更复杂的任务,LLM嵌入可能提供更深层次的语义理解。
延伸问答
在文本分类中,哪种模型组合表现最好?
TF-IDF与支持向量机组合在分类准确率上最佳,达到0.987。
LLM嵌入在聚类任务中的表现如何?
LLM嵌入在聚类任务中表现更佳,调整兰德指数(ARI)为0.899。
在处理简单数据集时,推荐使用哪种文本表示方法?
建议在处理简单数据集时优先考虑传统方法,如TF-IDF和BoW。
为什么LLM嵌入在某些情况下未必优于传统方法?
因为简单且线性可分的数据集上,传统方法足以捕捉模式,LLM嵌入可能导致过拟合。
在文本分类中,哪种方法的训练时间最短?
LLM嵌入与支持向量机的训练时间最短,仅需0.15秒。
词袋模型在文本处理中的适用场景是什么?
词袋模型适用于非常简单的任务,要求最大可解释性,或作为基线模型的一部分。
