
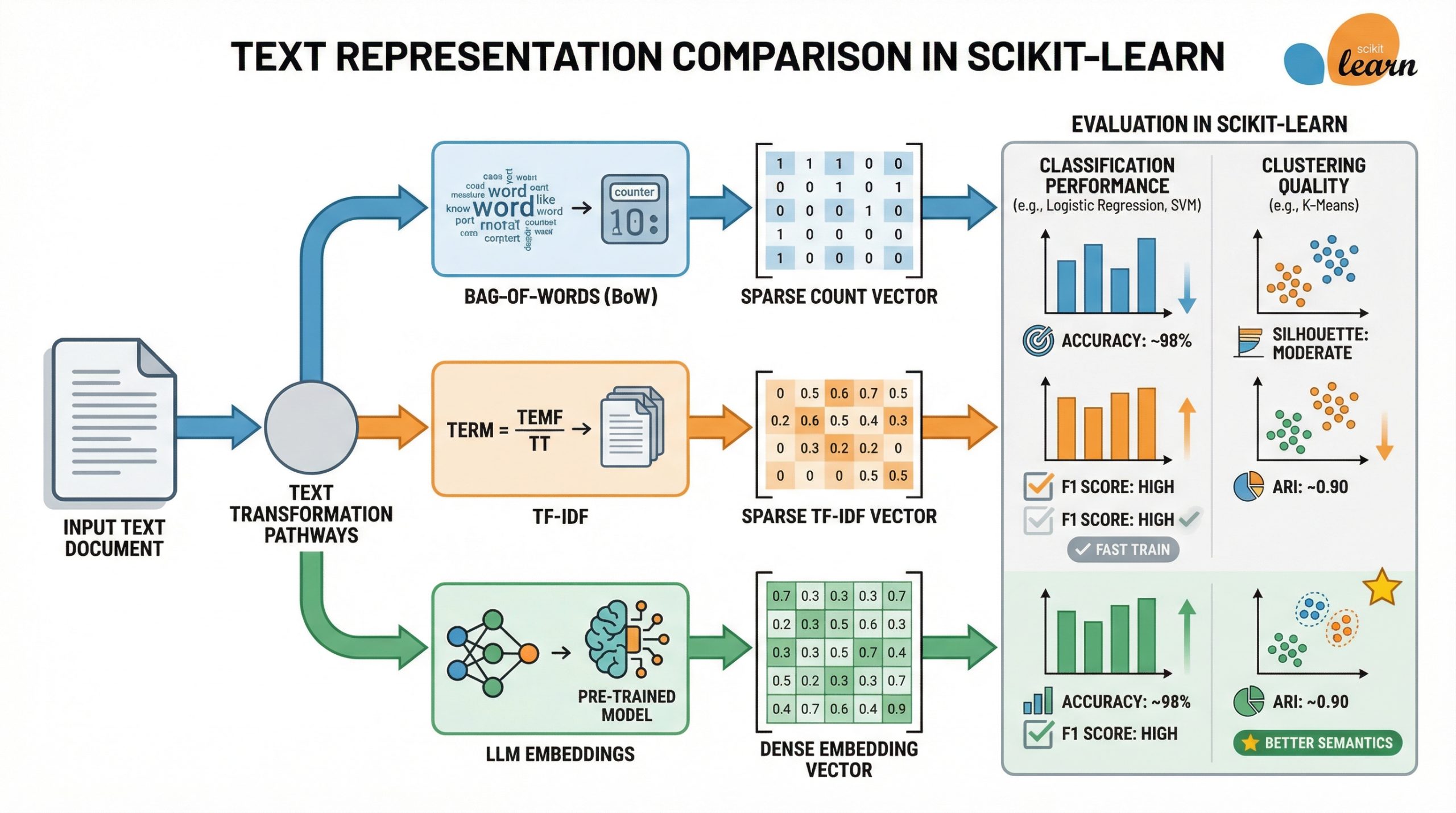
LLM嵌入与TF-IDF与词袋模型:在Scikit-learn中哪种效果更好?
MachineLearningMastery.com
·

后期分块:利用长上下文语言模型增强上下文块表示
DEV Community
·

DDNLP:深入NLP
Sekyoro的博客小屋
·
