

Scikit-Ollama用于Scikit-LLM/Ollama集成
MachineLearningMastery.com
·

使用Scikit-LLM与开源语言模型
MachineLearningMastery.com
·

Scikit-LLM与传统文本分类器的比较:何时应使用LLM?
MachineLearningMastery.com
·

在PyCharm中使用词袋模型
The JetBrains Blog
·
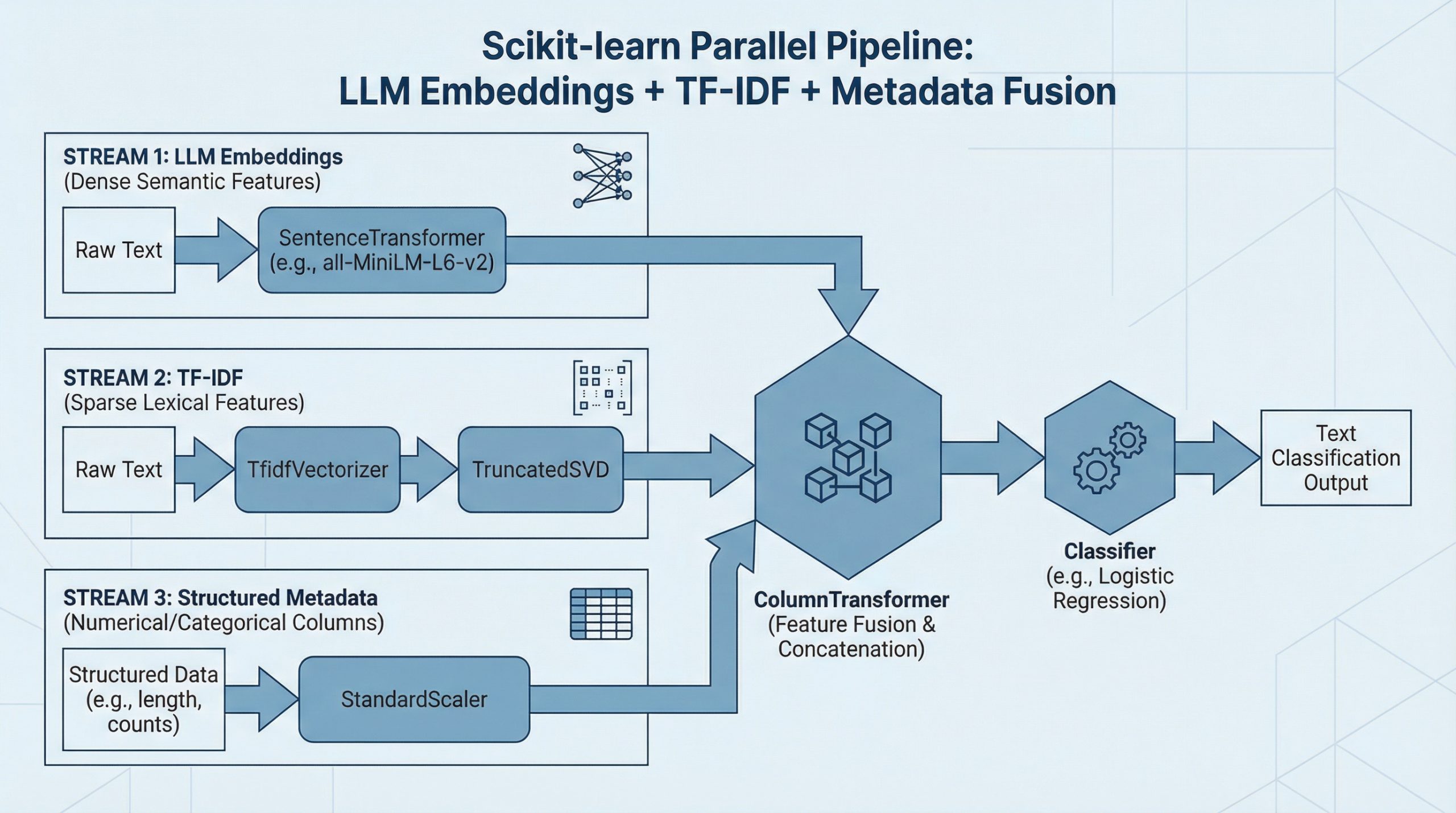
如何在一个Scikit-learn管道中结合LLM嵌入、TF-IDF和元数据
MachineLearningMastery.com
·
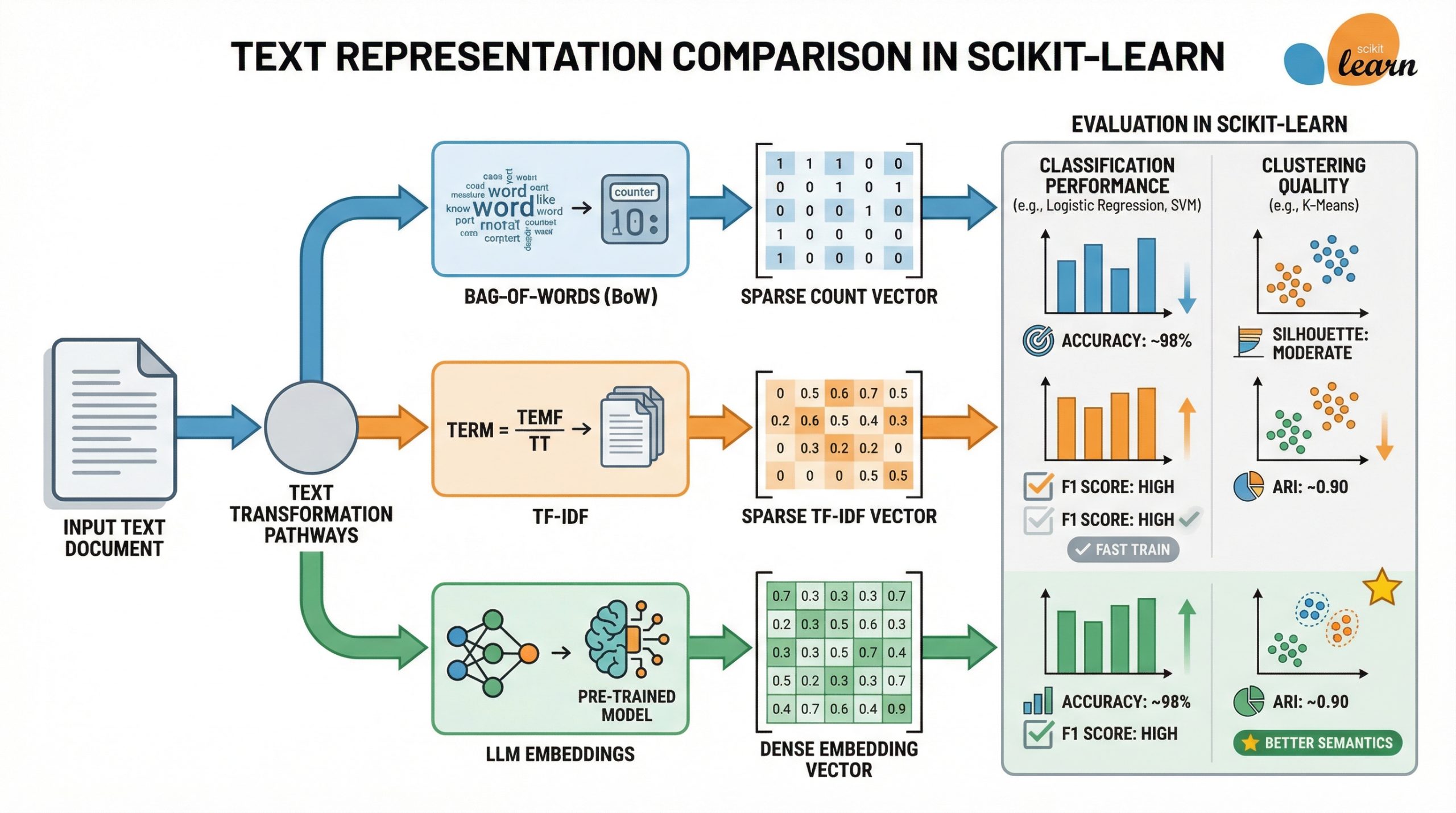
LLM嵌入与TF-IDF与词袋模型:在Scikit-learn中哪种效果更好?
MachineLearningMastery.com
·

第721期:使用zstd、可调用对象、Gemini等进行分类(2026年2月10日)
PyCoder’s Weekly
·

如何使用Natural库在JavaScript中进行基本的自然语言处理
The New Stack
·
![如何在项目中使用自然语言处理技术和工具 [完整手册]](https://cdn.hashnode.com/res/hashnode/image/upload/v1763743424066/393a4384-ce7a-4ff8-9e98-1edaaa322bc6.png)
如何在项目中使用自然语言处理技术和工具 [完整手册]
freeCodeCamp.org
·

为什么以及何时使用句子嵌入而非词嵌入
MachineLearningMastery.com
·


使用决策树理解文本
MachineLearningMastery.com
·

使用Scikit-LLM进行零样本和少样本分类
MachineLearningMastery.com
·

VisualStudio.Extensibility:编辑器分类与用户提示更新
Visual Studio Blog
·
