
如何在一个Scikit-learn管道中结合LLM嵌入、TF-IDF和元数据
内容提要
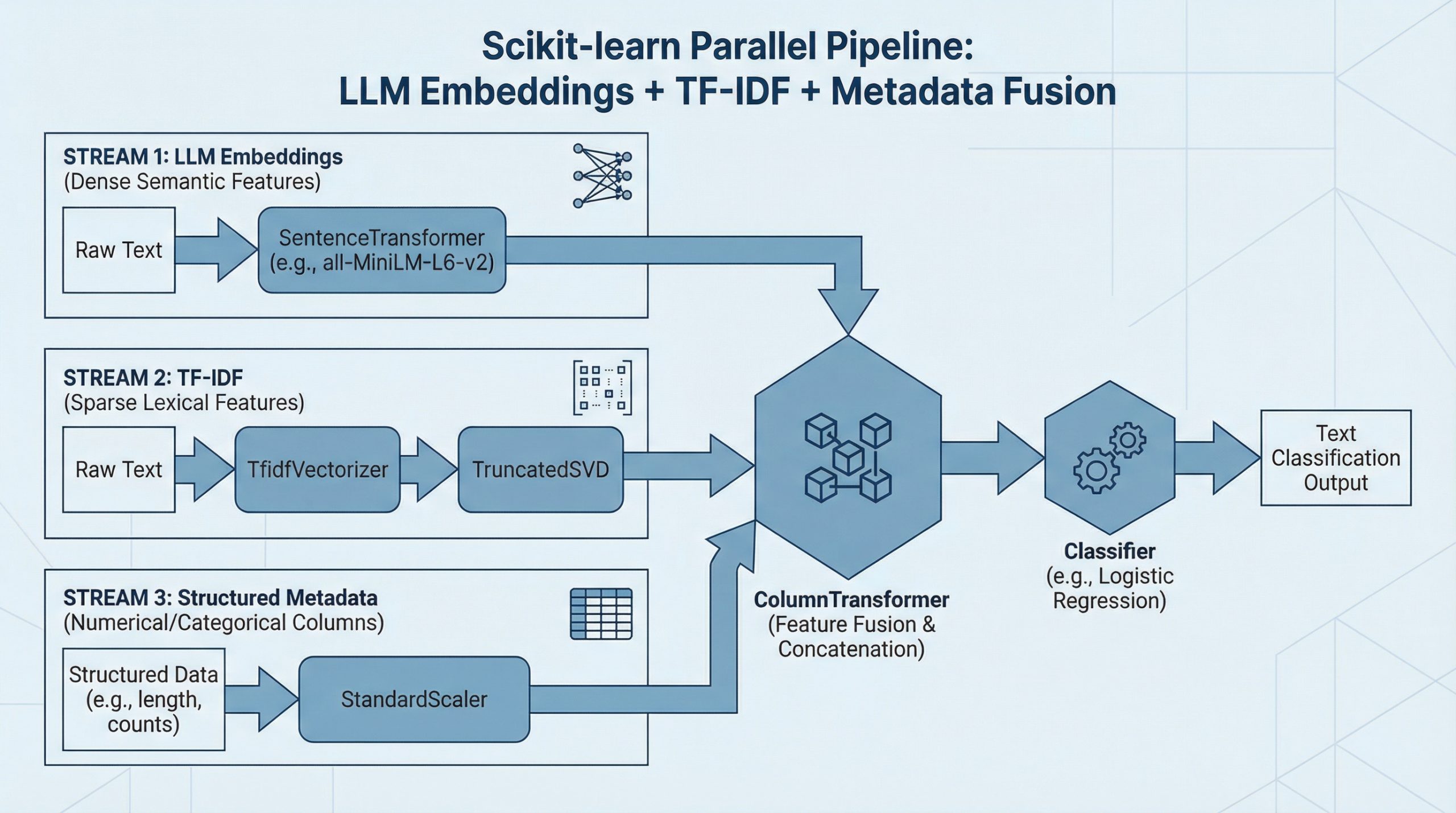
本文介绍了如何在scikit-learn管道中结合LLM嵌入、TF-IDF特征和结构化元数据进行文本分类。主要步骤包括加载数据集、构建特征管道、融合特征以及训练分类器,以实现高效的文本分类模型。
关键要点
-
本文介绍了如何在scikit-learn管道中结合LLM嵌入、TF-IDF特征和结构化元数据进行文本分类。
-
主要步骤包括加载数据集、构建特征管道、融合特征以及训练分类器。
-
使用fetch_20newsgroups数据集,提取特定类别的新闻文章作为文本数据。
-
生成结构化元数据特征,包括字符长度、单词计数、平均单词长度、大写字母比例和数字比例。
-
在提取LLM嵌入和TF-IDF特征之前,先将数据分为训练集和测试集,以避免信息泄露。
-
定义EmbeddingTransformer类以生成自定义LLM嵌入,并构建TF-IDF、LLM嵌入和元数据的并行管道。
-
使用ColumnTransformer将三个特征管道融合在一起,并与逻辑回归分类器结合形成完整的管道。
-
通过训练完整的管道,进行模型训练并在测试集上进行预测,评估分类器的性能。
延伸解读
数据融合的重要性
在文本分类任务中,结合多种特征源(如LLM嵌入、TF-IDF和元数据)能够显著提升模型的性能。通过融合不同类型的信息,模型可以更全面地理解文本内容,从而提高分类准确性。
特征提取的顺序
在构建管道时,确保在提取LLM嵌入和TF-IDF特征之前先进行数据集的划分是至关重要的。这可以避免信息泄露,确保模型训练的公正性和有效性。
使用ColumnTransformer的优势
ColumnTransformer允许在同一管道中处理不同类型的特征,使得特征融合变得更加高效和灵活。通过这种方式,可以轻松地将文本特征与结构化元数据结合,提升模型的表现。
延伸问答
如何在Scikit-learn中构建文本分类管道?
可以通过加载数据集、构建特征管道、融合特征并训练分类器来构建文本分类管道。
LLM嵌入和TF-IDF特征如何结合使用?
LLM嵌入和TF-IDF特征可以通过并行管道结合,并使用ColumnTransformer进行融合。
在文本分类中,如何生成结构化元数据特征?
可以通过计算字符长度、单词计数、平均单词长度、大写字母比例和数字比例来生成结构化元数据特征。
为什么在提取特征之前需要分割数据集?
分割数据集可以避免信息泄露,确保特征提取过程只在训练集上进行。
如何评估训练好的文本分类模型的性能?
可以通过在测试集上进行预测并使用分类报告来评估模型性能。
Scikit-learn管道中如何处理不同类型的特征?
可以使用ColumnTransformer将不同类型的特征管道融合在一起,处理文本、LLM嵌入和元数据特征。
