

Scikit-LLM与传统文本分类器的比较:何时应使用LLM?
MachineLearningMastery.com
·
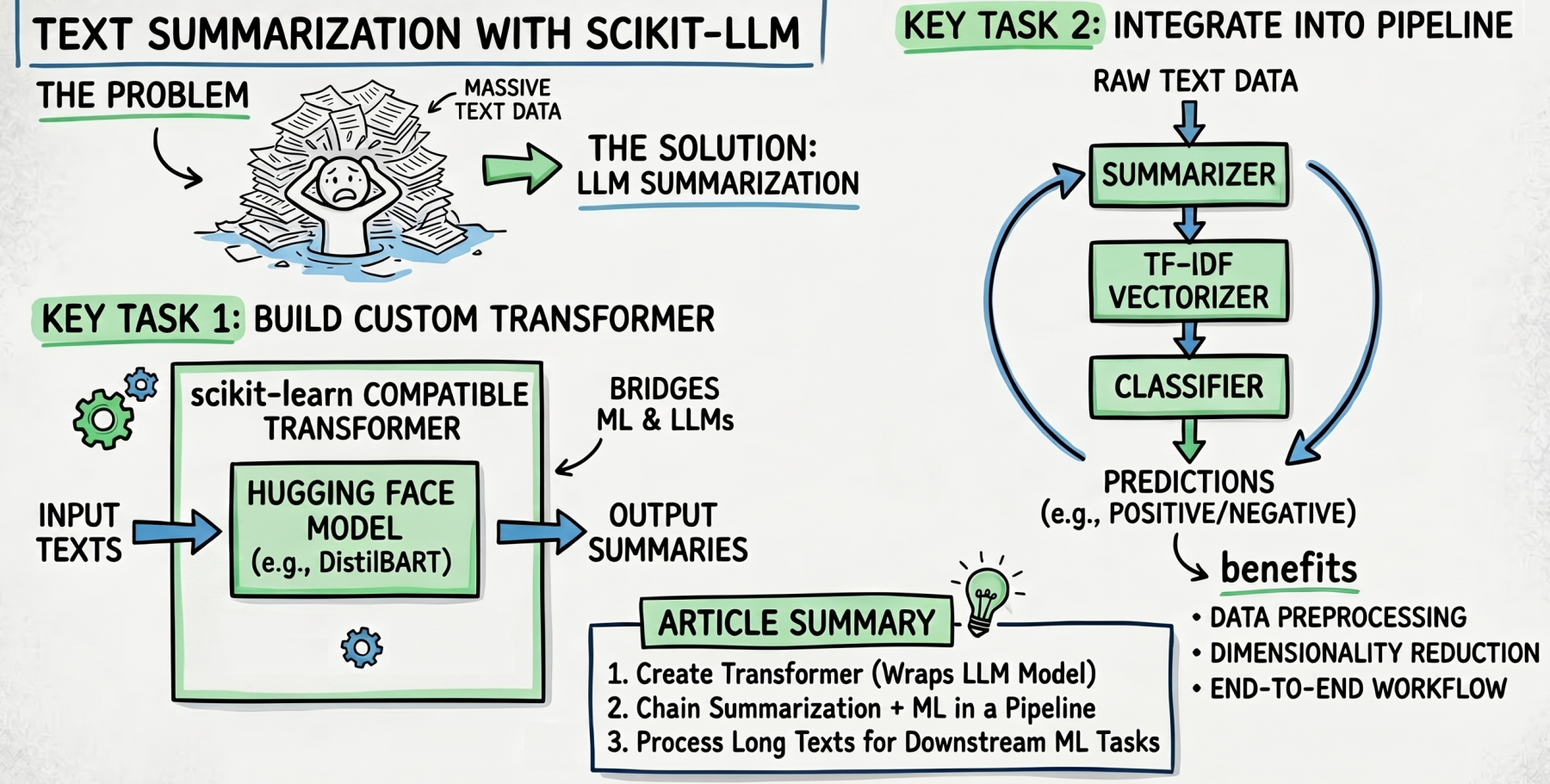
使用Scikit-LLM进行文本摘要
MachineLearningMastery.com
·
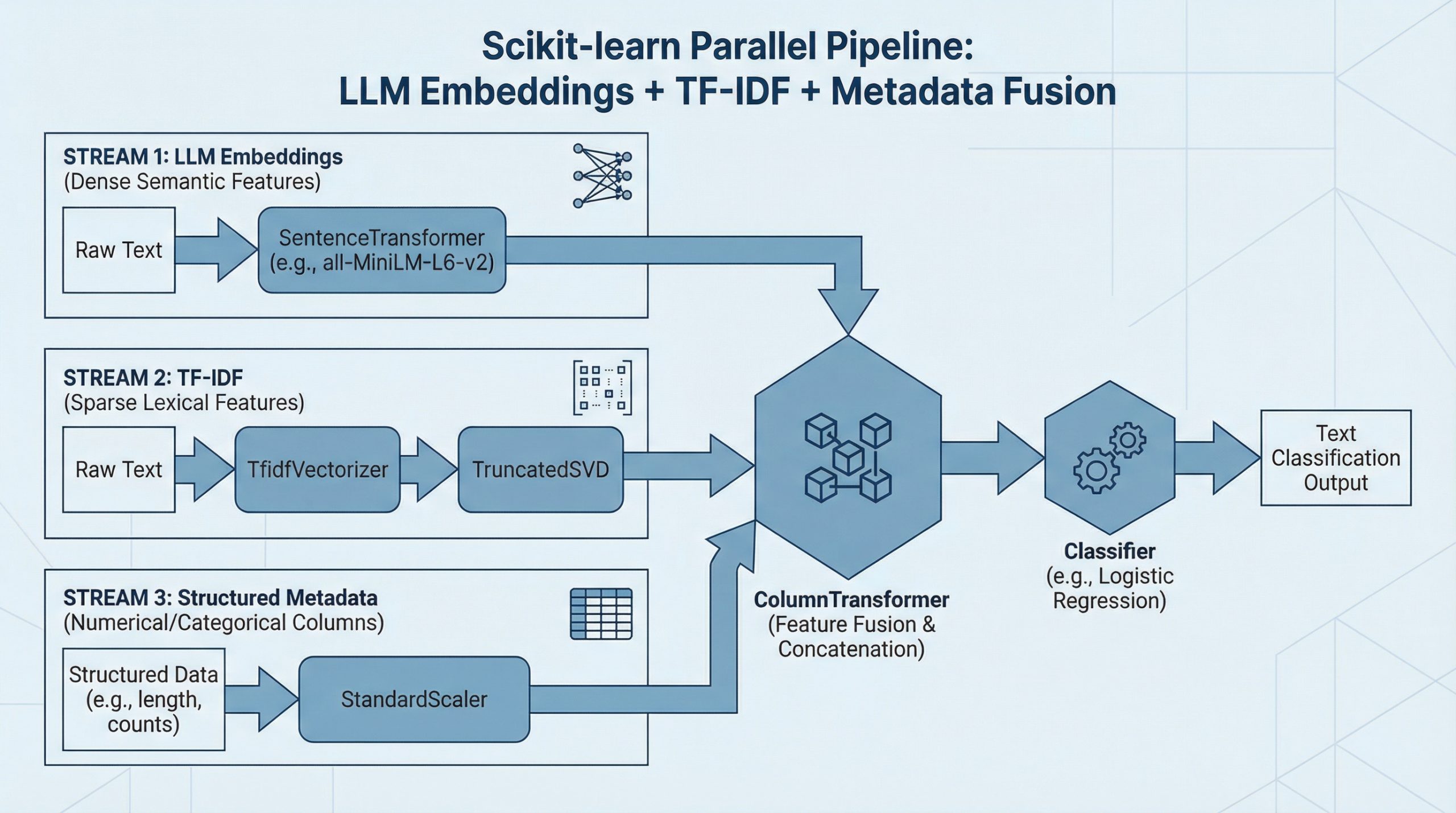
如何在一个Scikit-learn管道中结合LLM嵌入、TF-IDF和元数据
MachineLearningMastery.com
·
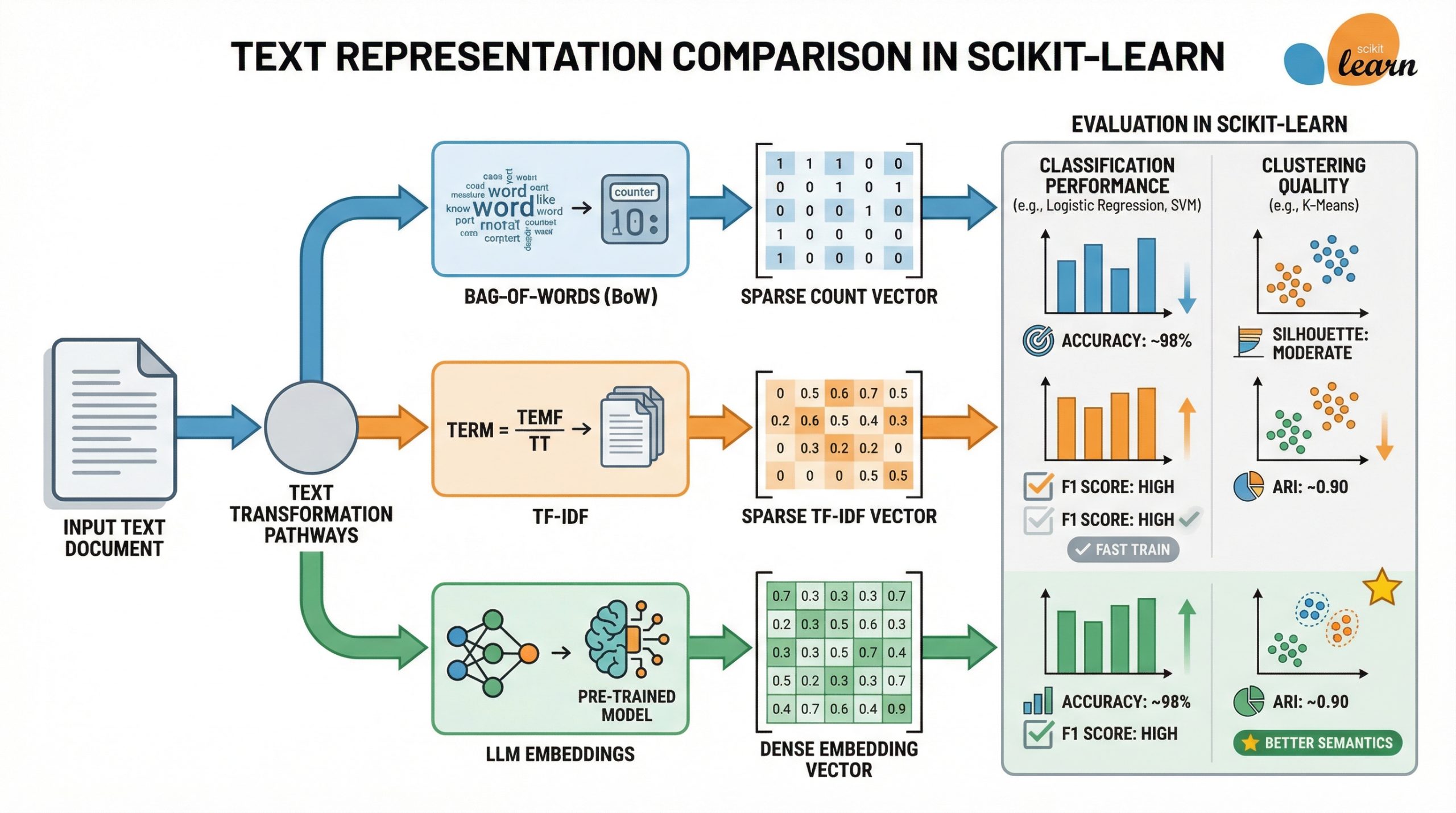
LLM嵌入与TF-IDF与词袋模型:在Scikit-learn中哪种效果更好?
MachineLearningMastery.com
·
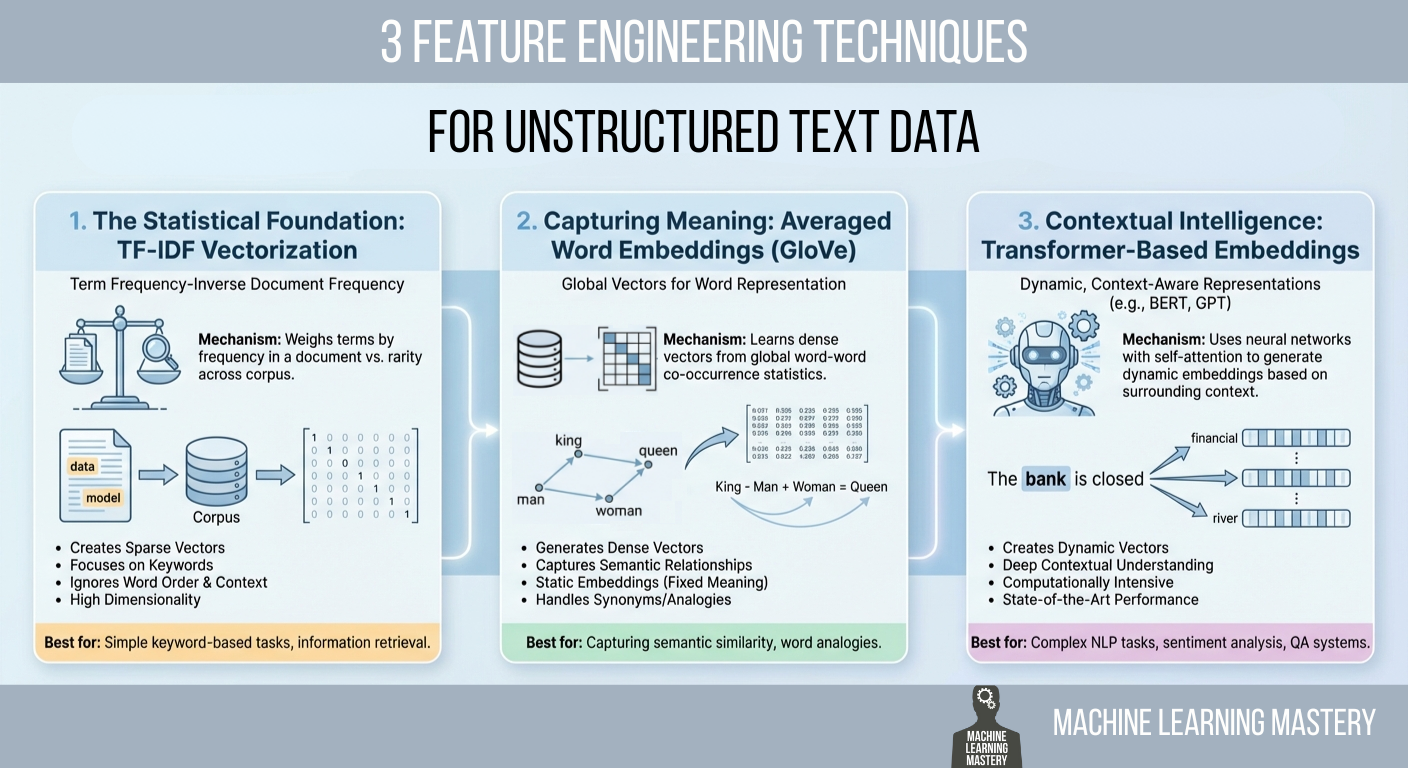
针对非结构化文本数据的三种特征工程技术
MachineLearningMastery.com
·

词袋模型的工作原理 – 语言模型的基础
freeCodeCamp.org
·



基于动态三元组图嵌入的上下文敏感语义推理
DEV Community
·

使用TF-IDF和逻辑回归进行垃圾邮件检测
DEV Community
·

为RAG实现上下文检索
DEV Community
·

在PHP和PostgreSQL中使用TF-IDF向量
DEV Community
·
