
针对非结构化文本数据的三种特征工程技术
内容提要
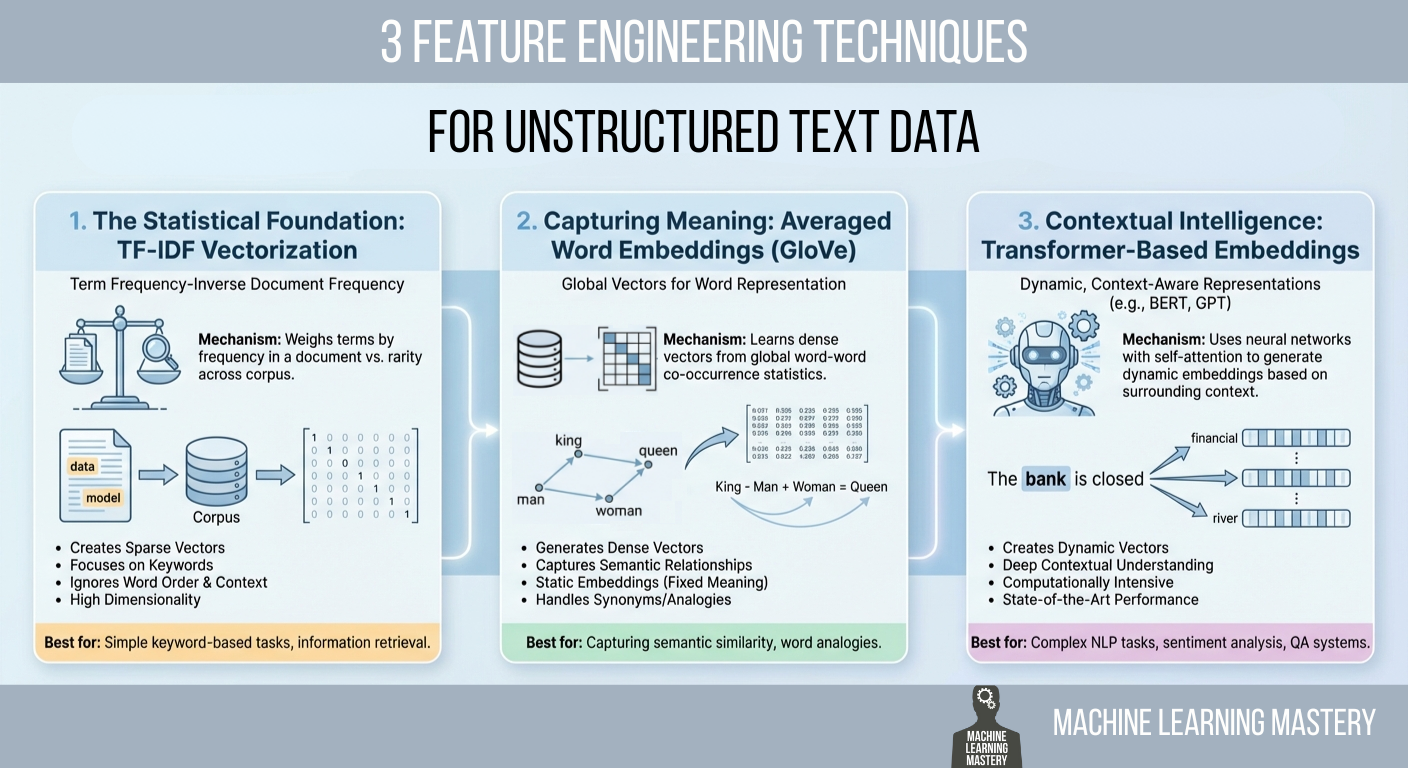
本文介绍了将原始文本转换为机器学习模型可用的数值特征的方法,包括TF-IDF、GloVe词嵌入和基于变换器的嵌入。TF-IDF通过词频和文档频率突出文档独特性;GloVe通过词向量捕捉语义;变换器模型(如BERT)提供上下文感知的表示。选择方法需根据具体需求和资源限制。
关键要点
-
机器学习模型无法直接处理原始文本,需要将其转换为数值特征。
-
特征工程是将人类语言的定性细微差别转化为机器可处理的定量数字列表的过程。
-
TF-IDF是一种统计方法,通过词频和文档频率来突出文档的独特性。
-
GloVe词嵌入通过将词映射到向量来捕捉语义,允许模型理解同义词和类比。
-
变换器模型(如BERT)提供上下文感知的表示,能够理解词语的上下文和顺序。
-
选择特征工程方法时需考虑具体需求和资源限制,TF-IDF适合简单任务,变换器适合复杂任务。
延伸解读
特征工程的重要性
特征工程在机器学习中扮演着关键角色,尤其是在处理非结构化文本数据时。选择合适的特征工程方法可以显著提升模型的性能。TF-IDF适合简单任务,而变换器模型则适用于需要深度语义理解的复杂任务。理解这些方法的优缺点,有助于在实际应用中做出更明智的选择。
TF-IDF与GloVe的比较
TF-IDF和GloVe在处理文本数据时各有千秋。TF-IDF强调文档的独特性,适合关键词匹配,而GloVe则通过词向量捕捉语义关系,能够理解同义词和类比。在选择时,需考虑任务的复杂性和对语义理解的需求,以便选择最合适的特征工程技术。
变换器模型的优势与挑战
变换器模型如BERT提供了上下文感知的文本表示,能够理解词语的语境和顺序,适合复杂的自然语言处理任务。然而,这类模型对计算资源的要求较高,使用时需考虑硬件条件和处理时间。对于资源有限的项目,可能需要权衡使用更轻量级的方法。
延伸问答
TF-IDF是什么,它如何工作?
TF-IDF是一种统计方法,通过词频和文档频率来突出文档的独特性。它通过惩罚常见词并奖励独特词来平衡词的重要性。
GloVe词嵌入的优势是什么?
GloVe词嵌入通过将词映射到向量来捕捉语义,使得相似意义的词在向量空间中距离较近,能够理解同义词和类比。
变换器模型(如BERT)如何改善文本特征表示?
变换器模型使用自注意力机制,能够理解词语的上下文和顺序,从而提供上下文感知的表示,解决了平均词嵌入忽略顺序的问题。
在特征工程中,如何选择合适的方法?
选择特征工程方法时需考虑具体需求和资源限制,TF-IDF适合简单任务,而变换器适合复杂任务。
TF-IDF和GloVe的主要区别是什么?
TF-IDF主要用于关键词匹配,强调文档的独特性,而GloVe则通过词向量捕捉语义关系,理解同义词和类比。
特征工程对机器学习模型的影响是什么?
特征工程是将人类语言的定性细微差别转化为机器可处理的定量数字列表,直接影响模型的成功与否。
