
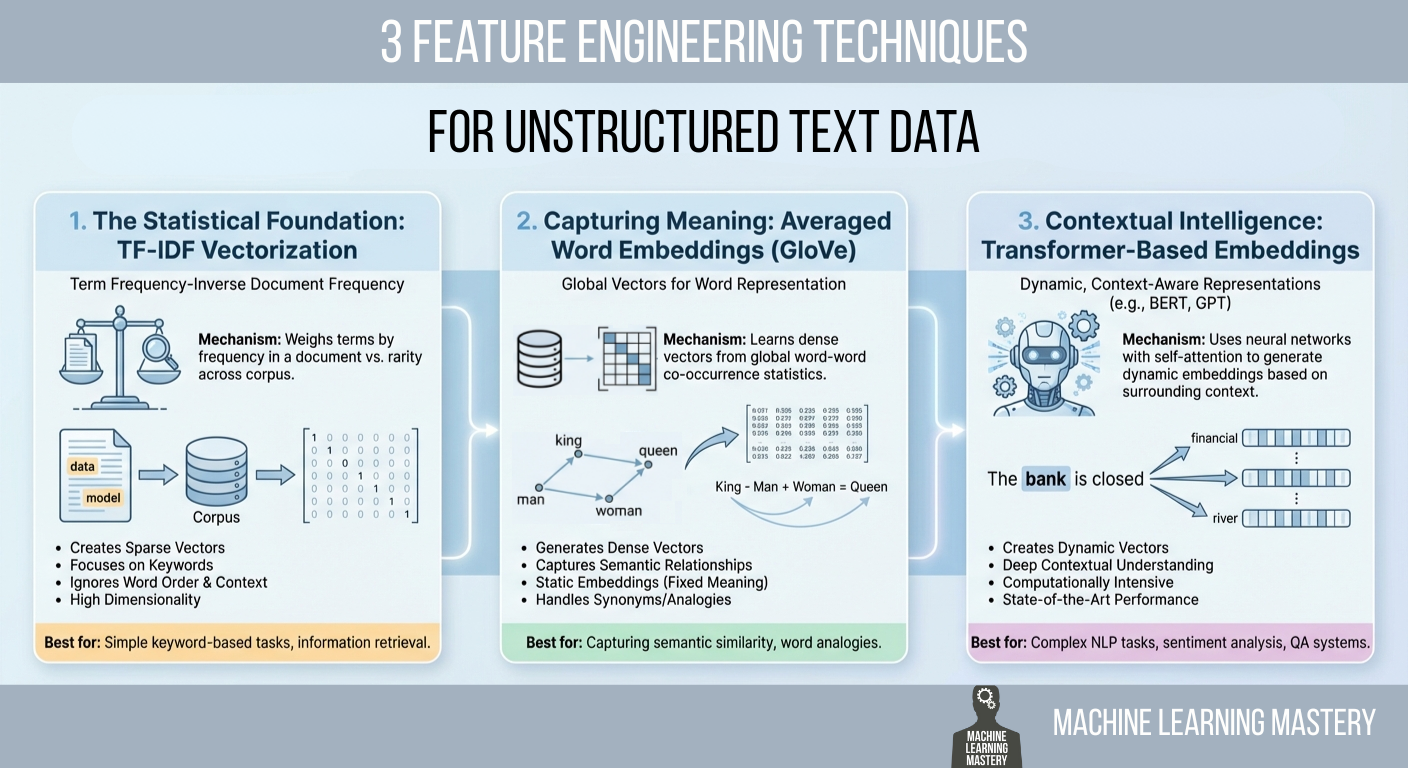
针对非结构化文本数据的三种特征工程技术
MachineLearningMastery.com
·

文本数据的七种特征工程技巧
MachineLearningMastery.com
·

如何窥探本地大型语言模型的内部运作
freeCodeCamp.org
·

为什么以及何时使用句子嵌入而非词嵌入
MachineLearningMastery.com
·

词袋模型的工作原理 – 语言模型的基础
freeCodeCamp.org
·

表格数据特征工程中的词嵌入
MachineLearningMastery.com
·

语言模型中的词嵌入
MachineLearningMastery.com
·

词嵌入与文本向量化的温和介绍
MachineLearningMastery.com
·

从词语到向量:词嵌入的温和入门
DEV Community
·
多语言语言模型如何处理多种语言?
BriefGPT - AI 论文速递
·
初学者必懂的六个语言模型概念
MachineLearningMastery.com
·


