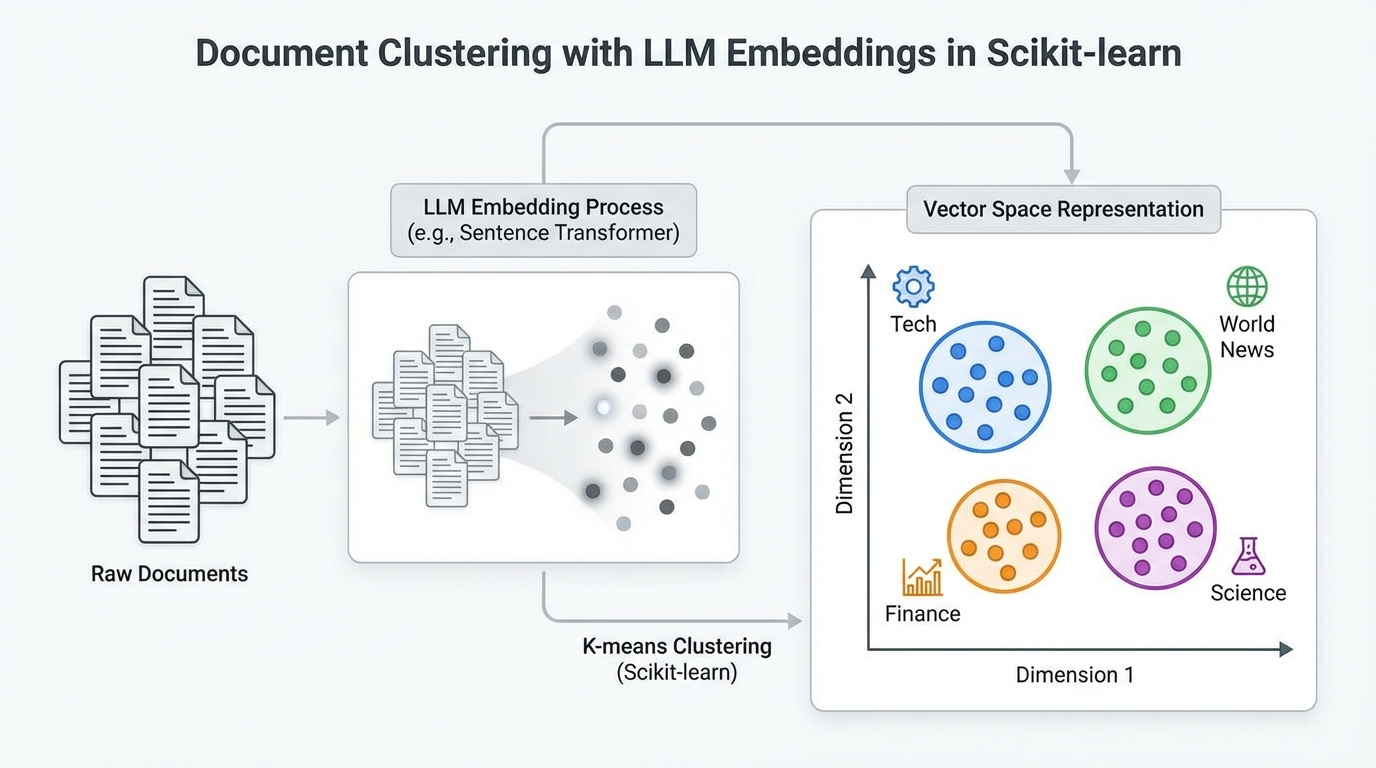
使用大语言模型嵌入在Scikit-learn中进行文档聚类
MachineLearningMastery.com
·

重新审视k-means:三种提升其性能的方法
MachineLearningMastery.com
·

Python中的聚类 – 机器学习工程手册
freeCodeCamp.org
·
![[Python-CV2] 图像分割:Canny边缘检测、Watershed算法和K-Means方法](https://media2.dev.to/dynamic/image/width=1000,height=500,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fzx5p64ogyhxbj59l8k56.png)
[Python-CV2] 图像分割:Canny边缘检测、Watershed算法和K-Means方法
DEV Community
·