本文介绍了如何结合大型语言模型(LLM)嵌入和HDBSCAN算法构建文本聚类管道,以自动发现未标记文本数据中的主题。主要步骤包括生成文本嵌入、降低维度和应用聚类,最终成功识别出两个主题聚类,展示了该方法的有效性。
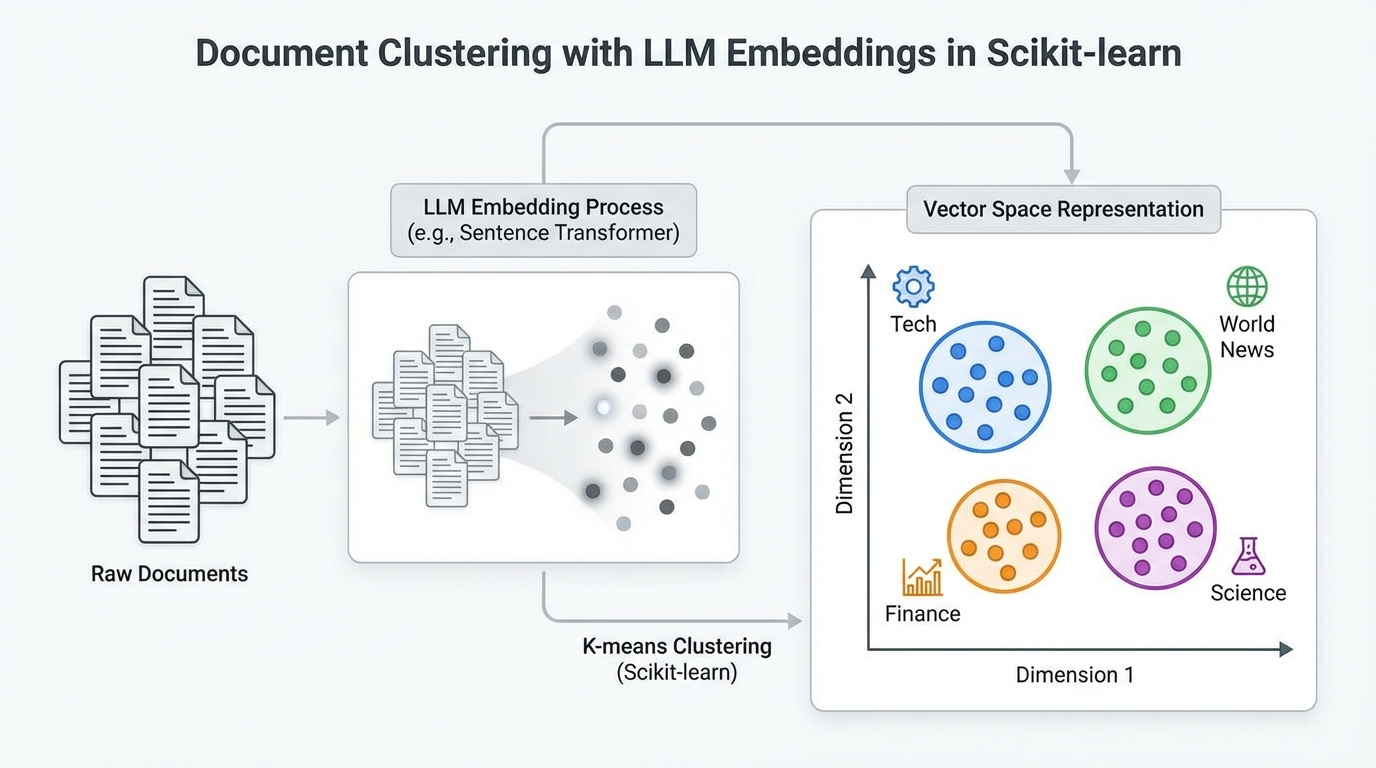
本文介绍了如何使用大语言模型嵌入和scikit-learn中的聚类算法对文本文件进行聚类,包括生成嵌入、应用k-means和DBSCAN算法,并评估效果。通过分析BBC新闻数据集,展示了识别文档共同主题的方法。
该研究提出了一种名为TECL的框架,旨在解决基于大型语言模型的文本聚类中的高计算和财务开销问题。TECL利用LLM反馈,在有限查询预算下实现高效且准确的无监督文本聚类,实验结果表明其在相同成本下优于现有方案。
本研究提出了一种新方法,利用大型语言模型(LLM)优化对话意图聚类,解决传统文本聚类与人类感知不匹配的问题。经过验证,精调的LLM在语义连贯性和聚类命名上表现优越,意图发现的应用效果显著,定量指标提高6.25%,应用层面性能提升12%。
自然语言处理(NLP)是计算机科学与人工智能的重要领域,旨在实现人与计算机的自然语言交流。文本聚类是NLP的一个应用,通过相似度将文本自动归类。传统的聚类方法如K-Means和层次聚类在特征选择和相似度度量上存在局限性,而深度学习方法通过文本表示学习和相似度计算显著提升了聚类效果。结合大语言模型进行聚类分析,展示了不同方法的优缺点。
本文探讨了文本嵌入、降维技术和漂移检测方法在文本数据分析中的有效性,强调了高维数据处理的挑战及深度学习在特征提取中的应用。研究提出了一种新工作流程,评估特征空间的稳定性,并揭示其对模型可解释性的影响。此外,分析了多语言模型在语义文本相似性任务中的表现,强调了文本聚类方法的改进和数据分布度量的有效性。
该研究探讨了大型语言模型(LLMs)在文本聚类中的应用,评估了嵌入对聚类结果的影响。结果表明,LLMs在捕捉语言细微差别方面表现优异,尤其是BERT优于其他轻量级模型。增加嵌入维度和使用摘要技术并不总能提高聚类效率,需谨慎分析。研究为文本分析提供了新的方向。
CLAM框架旨在提高自然语言生成系统在处理模糊问题时的准确性,通过用户澄清问题和自动评估对话质量来增强语言模型的表现。此外,研究提出了ClusterLLM文本聚类框架,利用大型语言模型的反馈来改善聚类效果,并探讨了在机器翻译中解决语义歧义的能力,展示了大型语言模型在处理模糊输入时的有效性。
ClusterLLM是一种新颖的文本聚类框架,利用大型语言模型(如ChatGPT)的反馈来提升聚类效果。研究表明,结合LLM特征和聚类方法能显著改善聚类性能,并帮助用户在精度与成本之间取得平衡。此外,UCTopic通过无监督对比学习提高了短语表示的效果,展示了LLM在主题提取和语义分割中的潜力。
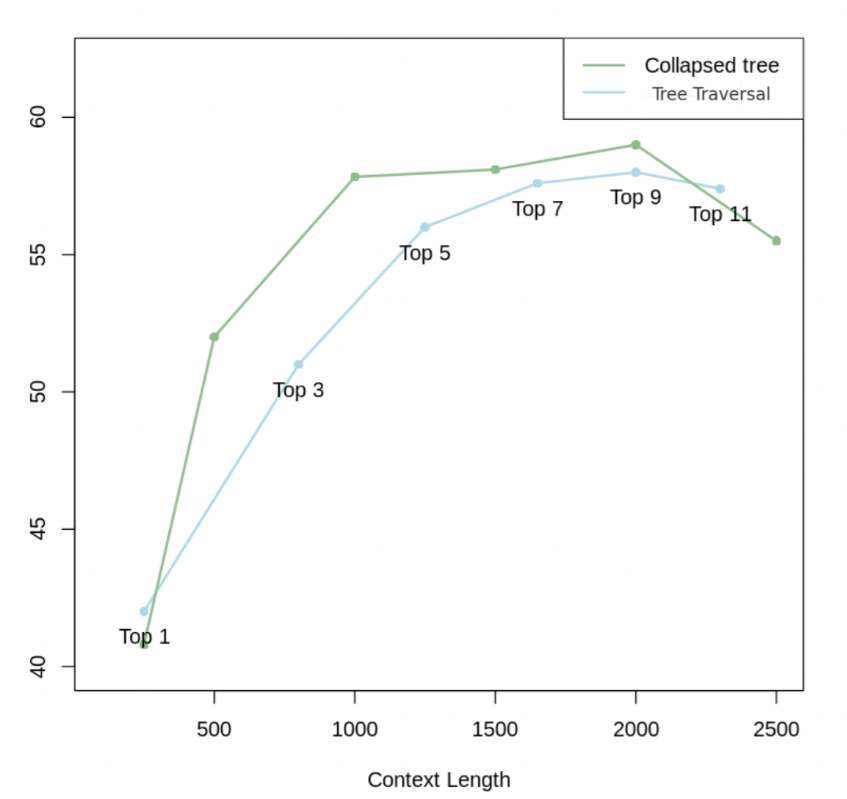
RAPTOR(递归抽象处理树状检索)是一种新方法,通过将文档构建为树状结构,逐层递归查询以提高对文档上下文的理解。结合GPT-4,RAPTOR在复杂问答任务中能提高20%的准确率。该方法使用高斯混合模型对文本块进行聚类,并生成摘要,以有效回答不同层面的问题。
完成下面两步后,将自动完成登录并继续当前操作。